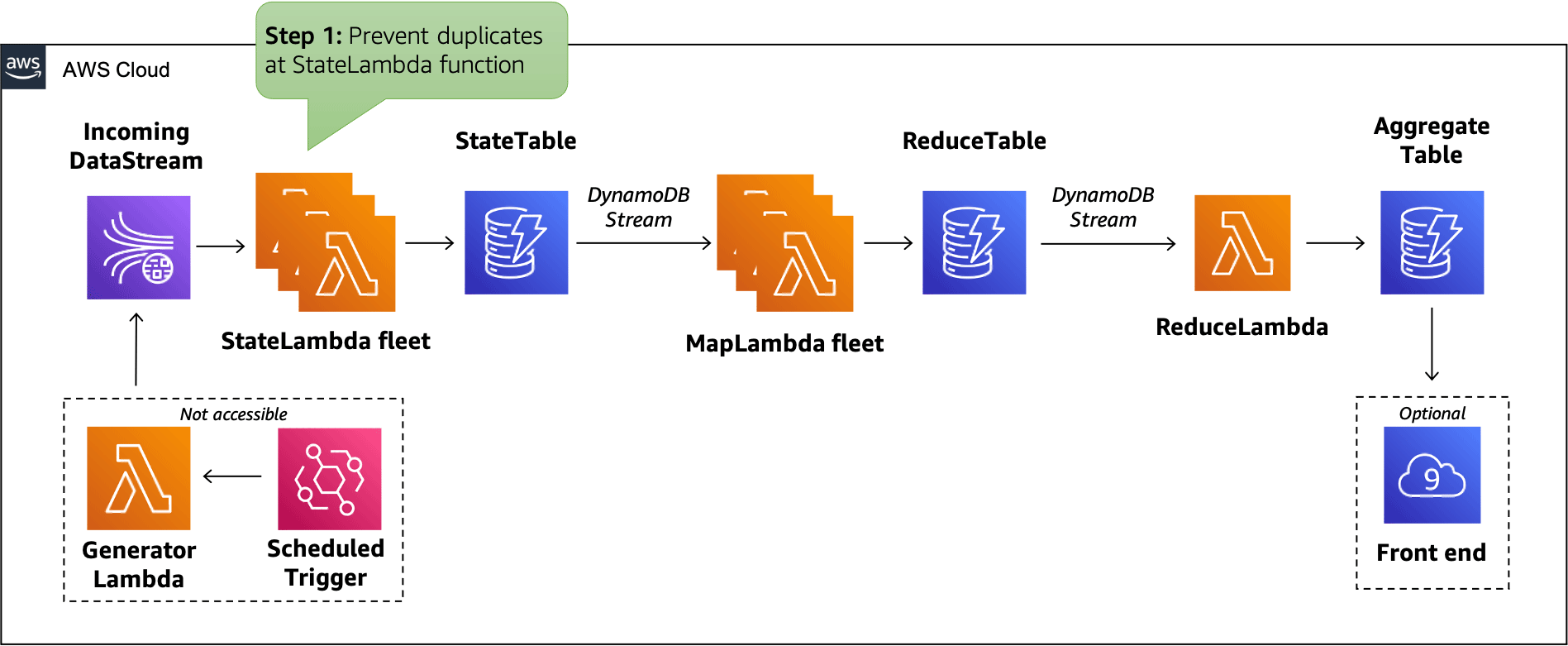
Step 1: Prevent duplicates at StateLambda function
The objective of this step is to modify the StateLambda function such that it does not successfully write duplicate messages to downstream resources.
Study the StateLambda code
- Use the AWS Management Console and navigate to the AWS Lambda service within the console.
- Click on the
StateLambdafunction to edit its configuration - Click on the
Codetab to access the Lambda function’s code
In the Lambda code browser, locate the code snipped below:
table.update_item(
Key = {
constants.STATE_TABLE_KEY: record_id
},
UpdateExpression = 'SET #VALUE = :new_value,' + \
'#VERSION = :new_version,' + \
'#HIERARCHY = :new_hierarchy,' + \
'#TIMESTAMP = :new_time',
ExpressionAttributeNames={
'#VALUE': constants.VALUE_COLUMN_NAME,
'#VERSION': constants.VERSION_COLUMN_NAME,
'#HIERARCHY': constants.HIERARCHY_COLUMN_NAME,
'#TIMESTAMP': constants.TIMESTAMP_COLUMN_NAME
},
ExpressionAttributeValues={
':new_version': record_version,
':new_value': Decimal(str(record_value)),
':new_hierarchy': json.dumps(record_hierarchy, sort_keys = True),
':new_time': Decimal(str(record_time))
}
)
This method call constructs an UpdateItem operation with the following properties:
- A write will be done on the attributes listed in the UpdateExpression:
- The value, version, hierarchy, and timestamp will be set with the provided values in the
ExpressionAttributeValues. - The attribute names as defined in
ExpressionAttributeNamesare pulled from constants we defined outside of this function file.
- The value, version, hierarchy, and timestamp will be set with the provided values in the
- The value of the
STATE_TABLE_KEYvariable contains the partition key name, and the value of the attribute will be therecord_id. - Notably, this write has no conditional checks to prevent duplicate writes.
Modify table.update_item statement to include conditional expression
Now, let’s compare it to the following snippet below:
table.update_item(
Key = {
constants.STATE_TABLE_KEY: record_id
},
ConditionExpression = 'attribute_not_exists(' + constants.STATE_TABLE_KEY + ') OR ' + constants.VERSION_COLUMN_NAME + '< :new_version',
UpdateExpression = 'SET #VALUE = :new_value,' + \
'#VERSION = :new_version,' + \
'#HIERARCHY = :new_hierarchy,' + \
'#TIMESTAMP = :new_time',
ExpressionAttributeNames={
'#VALUE': constants.VALUE_COLUMN_NAME,
'#VERSION': constants.VERSION_COLUMN_NAME,
'#HIERARCHY': constants.HIERARCHY_COLUMN_NAME,
'#TIMESTAMP': constants.TIMESTAMP_COLUMN_NAME
},
ExpressionAttributeValues={
':new_version': record_version,
':new_value': Decimal(str(record_value)),
':new_hierarchy': json.dumps(record_hierarchy, sort_keys = True),
':new_time': Decimal(str(record_time))
}
)
The code in line 5 adds a compound condition that ensures an item is only inserted if it doesn’t already exist, or if it does then then it should be replaced if the new item has a greater version number (e.g. is a newer version of the item). This is the simplified version of that condition expression:
attribute_not_exists(‘PRIMARY KEY’) OR ‘CURRENT VERSION’ < ‘NEW VERSION’
To explain, the condition first states that at the moment of data insertion the table should not contain an item with partition key pk equal to the record_id or else the write should fail (see the attribute_not_exists function ), implying this is the first time such a item/message is inserted. Then, with the inclusion of the OR keyword the condition says that if a row is already present in the table and the version number of the row being inserted is greater than the current row then the write should succeed.
You don’t need to change anything in your Lambda code yet, this will come in just a minute if you read on.
Why does it work?
This conditional expression allows us to detect and handle cases when a message is duplicated by the upstream components, or if some messages came out of order. These situations can occur if the upstream Lambda puts the same message into the Kinesis stream more than once, for example. In such cases a ConditionalCheckFailedException error is raised and no data is inserted into the database. Next we need to modify our code to correctly handle these errors as they are normal and expected now.
Catch a ClientError exception and deploy the changes
We want to avoid failing and subsequently restarting the Lambda function, so we will add a proper error handler in case we have an exception on the conditional write. It’s a best practice to check the name of an exception, e.g. e.response['Error']['Code'], to determine whether the exception is normal or indicates a deeper problem.
The following code snippet suppresses ConditionalCheckFailedException errors while raising an error for all other exceptions:
try:
table.update_item(
Key = {
constants.STATE_TABLE_KEY: record_id
},
ConditionExpression = 'attribute_not_exists(' + constants.STATE_TABLE_KEY + ') OR ' + constants.VERSION_COLUMN_NAME + '< :new_version',
UpdateExpression = 'SET #VALUE = :new_value,' + \
'#VERSION = :new_version,' + \
'#HIERARCHY = :new_hierarchy,' + \
'#TIMESTAMP = :new_time',
ExpressionAttributeNames={
'#VALUE': constants.VALUE_COLUMN_NAME,
'#VERSION': constants.VERSION_COLUMN_NAME,
'#HIERARCHY': constants.HIERARCHY_COLUMN_NAME,
'#TIMESTAMP': constants.TIMESTAMP_COLUMN_NAME
},
ExpressionAttributeValues={
':new_version': record_version,
':new_value': Decimal(str(record_value)),
':new_hierarchy': json.dumps(record_hierarchy, sort_keys = True),
':new_time': Decimal(str(record_time))
}
)
except ClientError as e:
if e.response['Error']['Code']=='ConditionalCheckFailedException':
print('Conditional put failed.' + \
' This is either a duplicate or a more recent version already arrived.')
print('Id: ', record_id)
print('Hierarchy: ', record_hierarchy)
print('Value: ', record_value)
print('Version: ', record_version)
print('Timestamp: ', record_time)
else:
raise e
Copy the code snippet above and replace it with the existing table.update_item(...) statement in your StateLambda function code. Then click on Deploy to apply the changes.
The above change will also help avoid duplicate writes when the Lambda service retries the StateLambda function after it has previously failed with a batch of incoming messages. With this change we avoid writing duplicates into StateTable which ensures we do not generate additional messages in the downstream StateTable DynamoDB stream.
How do you know you fixed it?
Navigate to StateLambda and open Logs under the Monitor tab. Check the log messages by clicking on the hyperlinked LogStream cell and validate that you see the following string in the log lines: Conditional put failed. This is either a duplicate.... This message is produced by the exception handling code above. This tells us that the conditional expression is working as expected.