Exercise 2: Sequential and Parallel Table Scans
This exercise demonstrates the two methods of DynamoDB table scanning: sequential and parallel.
Even though DynamoDB distributes items across multiple physical partitions, a Scan operation can only read one partition at a time. To learn more, read our documentation page on partitions and data distribution . For this reason, the throughput of a Scan is constrained by the maximum throughput of a single partition.
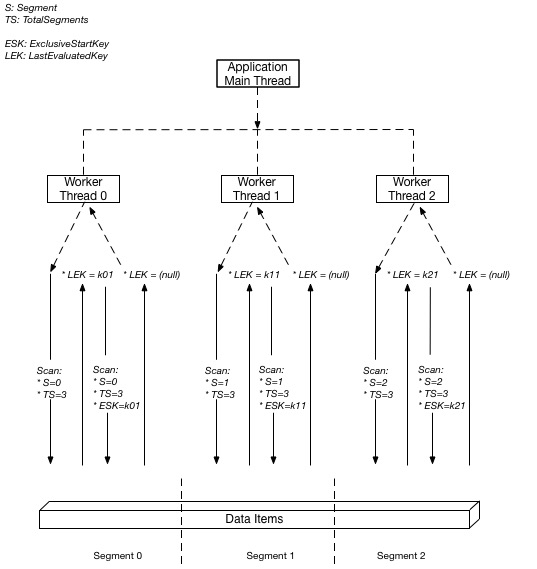
In order to maximize the utilization of table-level provisioning, use a parallel Scan to logically divide a table (or secondary index) into multiple logical segments, and use multiple application workers to scan these logical segments in parallel. Each application worker can be a thread in programming languages that support multithreading or an operating system process. To learn more about how to implement a parallel scan, read our developer documentation page on parallel scans . The Scan API is not suitable for all query patterns, and for more information on why scans are less efficient than queries please read about the performance implications of Scan in our documentation.
The following diagram shows how a multithreaded application performs a parallel Scan with three application worker threads. The application spawns three threads and each thread issues a Scan request, scans its designated segment, retrieving data 1 MB at a time, and returns the data to the main application thread.