Exercise 3: Global Secondary Index Write Sharding
The primary key of a DynamoDB table or a global secondary index consists of a partition key and an optional sort key. The way you design the content of those keys is extremely important for the structure and performance of your database. Partition key values determine the logical partitions in which your data is stored. Therefore, it is important to choose a partition key value that uniformly distributes the workload across all partitions in the table or global secondary index. For a discussion on how to choose the right partition key, see our blog titled Choosing the Right DynamoDB Partition Key .
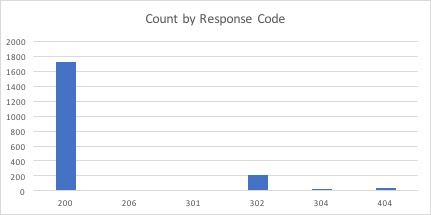
In this exercise, you learn about global secondary index write sharding, which is an effective design pattern to query selectively the items spread across different logical partitions in a very large table. Let’s review the server access logs example [from Exercise 1]{href="/design-patterns/ex1capacity"}, which is based on Apache service access logs. This time, you query the items with response code 4xx. Note that the items with response code 4xx are a very small percentage of the total data and do not have an even distribution by response code. For example, the response code 200 OK has more records than the others, which is as expected for any web application.
The following chart shows the distribution of the log records by response code for the sample file, logfile_medium1.csv.
You will create a write-sharded global secondary index on a table to randomize the writes across multiple logical partition key values. In effect, this increases the write and read throughput of the application. To apply this design pattern, you can create a random number from a fixed set (for example, 1 to 10), and use this number as the logical partition key for a global secondary index. Because you are randomizing the partition key, the writes to the table are spread evenly across all of the partition key values independent of any attribute. This will yield better parallelism and higher overall throughput. Also, if the application needs to query the log records by a specific response code on a specific date, you can create a composite sort key using a combination of the response code and the date.
In this exercise, you create a global secondary index using random values for the partition key, and the composite key responsecode#date#hourofday as the sort key. The logfile_scan table that you created and populated during the preparation phase of the workshop already has these two attributes. If you did not complete the setup steps, return to Setup - Step 6 and complete the step. These attributes were created using the following code.
SHARDS = 10
newitem['GSI_1_PK'] = "shard#{}".format((newitem['requestid'] % SHARDS) + 1)
newitem['GSI_1_SK'] = row[7] + "#" + row[2] + "#" + row[3]