Optional - Pipeline Deep Dive
Understanding how the pipeline works internally is recommended, however reading this page is not mandatory to complete the workshop.
This section explains in detail how the pipeline works from end-to-end. For a simplified explanation refer to the figure below where we have divided the pipeline into three stages. For each stage we outline the input and the output of the stage.
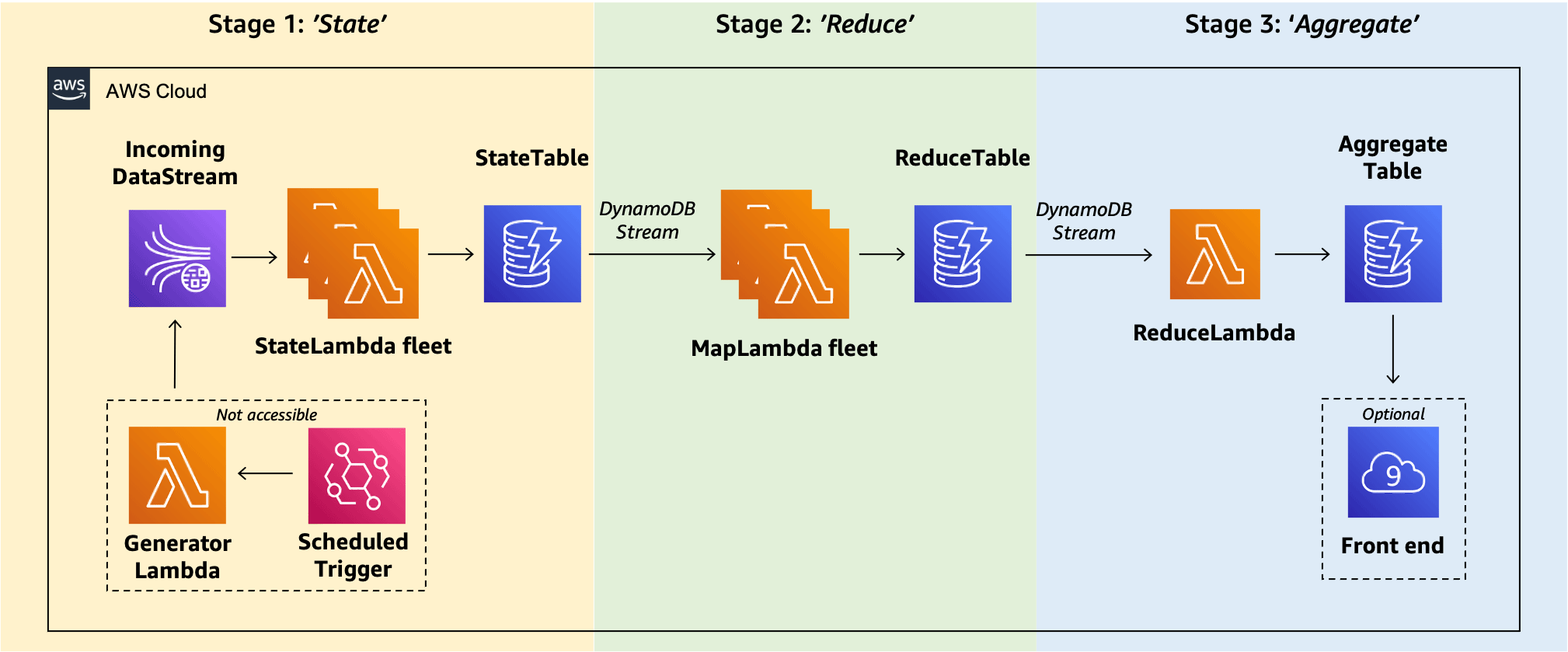
Stage 1: ‘State’
The business problem of near real-time data aggregation is faced by customers in various industries such as manufacturing, retail, gaming, utilities, and financial services. In this workshop we focus on the banking industry, and specifically on the problem of near real-time trade risk aggregation. Typically, financial institutions associate every trade that is performed on the trading floor with a risk value, and the risk management division of the bank needs a consistent view of the total risk values aggregated over all trades. In this workshop we use the following structure for risk messages:
{
"RiskMessage": {
"TradeID" : "0d957268-2913-4dbb-b359-5ec5ff732cac",
"Value" : 34624.51,
"Version" : 3,
"Timestamp" : 1616413258.8997078,
"Hierarchy" : {"RiskType": "Delta", "Region": "AMER", "TradeDesk": "FXSpot"}
}
}
TradeID: A unique identifier for each trade message.Value: The risk value (currency) associated with this trade.Version: The risk value of a trade sometimes needs to be modified at a later stage. This attribute keeps track of the latest known version for a given trade.Timestamp: The time when the trade occurred.Hierarchy: A list of attributes associated with this trade. To expand, this includes the type of risk, the region where the trade took place, and the type of the trading desk that performed the trade. These attributes will be used to group trades and aggregate the data.
Consider an example where five risk messages are ingested in the pipeline, as represented in the following figure. For visibility we labeled each message with an identifier from M1 to M5. Each message has a unique TradeID, a risk Value, and a group of hierarchy attributes (as explained above). For simplicity, all messages have the RiskType "Delta" and the Version attribute is always set to 1.
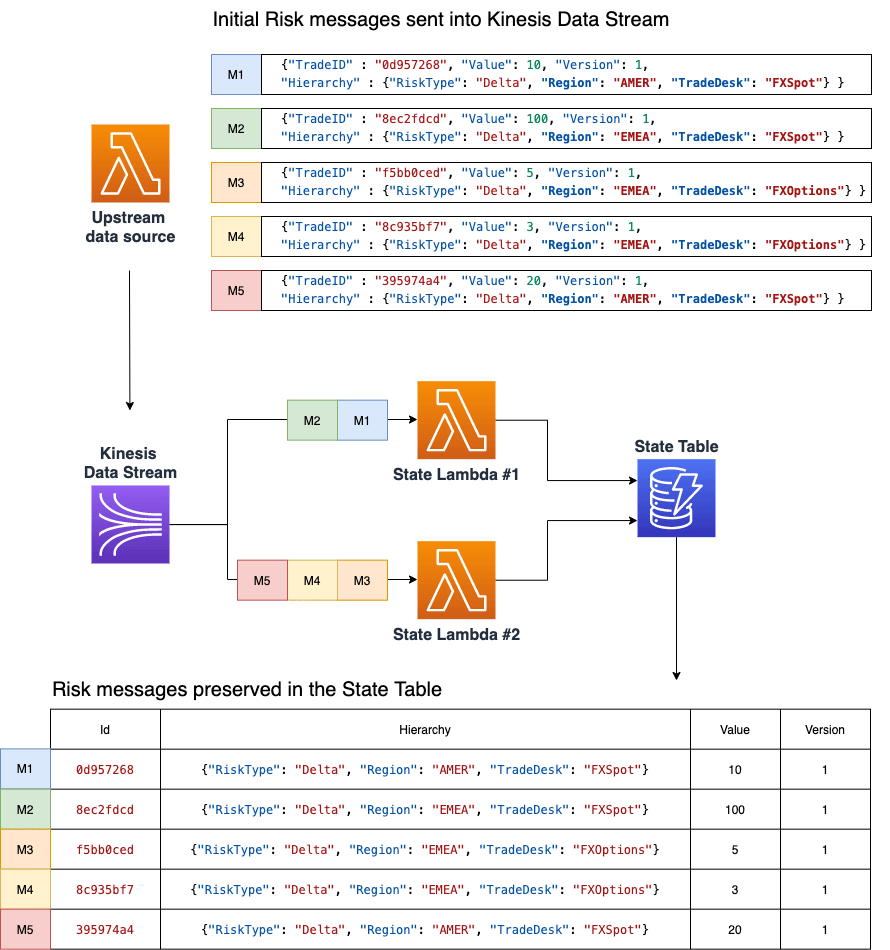
The pipeline is event driven by an upstream data source that writes records into a Kinesis Data Stream, and the StateLambda function is invoked to process these messages further.
As the rate of message arrival can be very high, multiple StateLambda functions will be invoked concurrently. This means that many simultaneous instances of the StateLambda function will run, each processing a subset of records. To learn more about Lambda function scaling, see the AWS Lambda function scaling documentation page which explains the concept of a Lambda instance. The example above shows the invocation of two StateLambda function instances labeled as #1 and #2. Instance #1 processes messages M1 and M2, while instance #2 processes messages M3, M4, and M5.
The responsibility of the StateLambda function is to preserve all incoming messages by writing them to the DynamoDB StateTable, and furthermore to ensure exactly once processing by keeping track of the unique ID of every that was processed at this stage. In this example both StateLambda functions write their respective messages into the DynamoDB StateTable. The StateTable at the bottom of the figure stores incoming risk messages without significant modifications.
Stage 2: ‘Reduce’
In Stage 2, all rows written into the StateTable are sent to the MapLambda for further processing by an event source mapping that connects the function to the DynamoDB stream of the StateTable. DynamoDB Streams ensure that every item change appears exactly once, and that all changes to a given item appear in the stream shards in the order they are written. However, multiple StateLambda functions write to different keys in the StateTable, and as a result the Stream records in the table’s stream might be in a different order than the order in which they were ingested in Stage 1.
In order to handle a high volume of incoming messages, multiple MapLambda instances are invoked to process messages from the StateTable DynamoDB stream, similar to Stage 1. In this example, MapLambda #1 takes messages M4, M3, and M1 while MapLambda #2 processes messages M5 and M2.
The responsibility of the MapLambda is to perform initial pre-aggregation of the messages, or more specifically to perform arithmetic summation based on the message attributes. The pre-aggregated output of each MapLambda function is written into the ReduceTable as a single row, as seen in “Output state of the ReduceTable” in the above figure. For simplicity, we refer to these rows as AM1 and AM2.
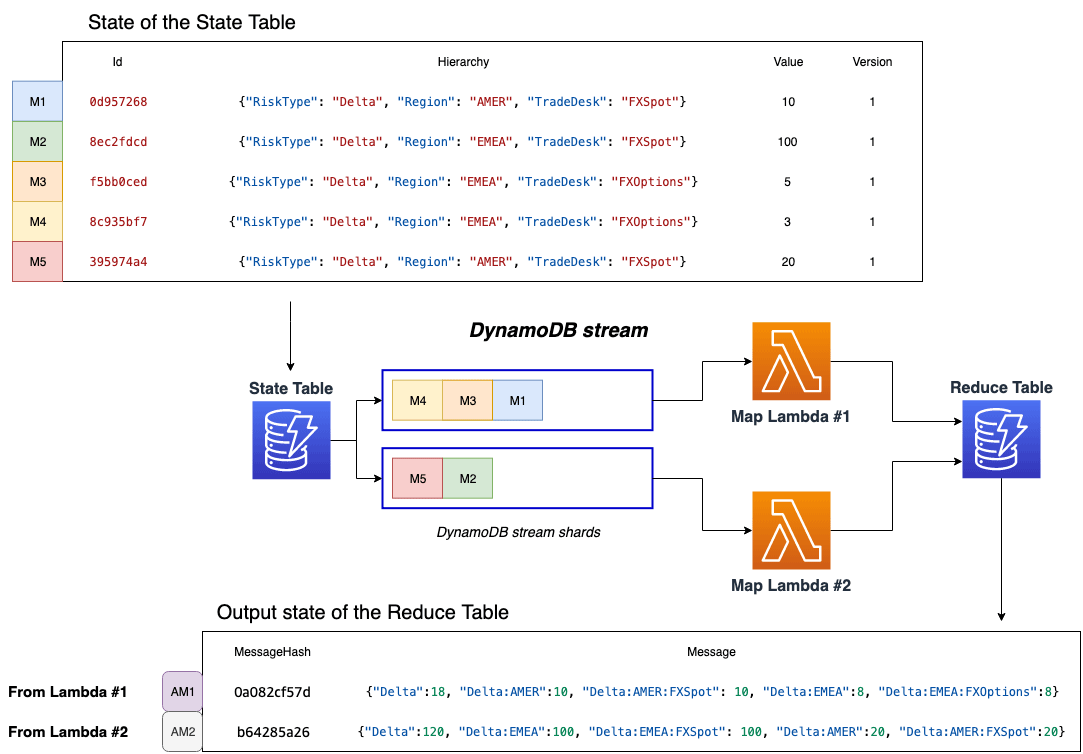
How does the pre-aggregation work?
Consider the second row, AM2, which combines messages M2 and M5. Based on the message attributes, the M2 message belongs to Delta::EMEA::FXSpot, while M5 message belongs to Delta::AMER::FXSpot. The common “denominator” for these trades is that both of them belong to the risk type Delta. Therefore, the Delta attribute in the ReduceTable is a sum of both messages, expressed as 100 + 20 = 120. Below are the messages M2 and M5 in JSON format for reference.
{"TradeID" : "8ec2fdcd", "Value": 100, "Version": 1,
"Hierarchy" : {"RiskType": "Delta", "Region": "EMEA", "TradeDesk": "FXSpot"} }
{"TradeID" : "395974a4", "Value": 20, "Version": 1,
"Hierarchy" : {"RiskType": "Delta", "Region": "AMER", "TradeDesk": "FXSpot"} }
Stage 3: ‘Aggregate’
In Stage 3, all rows written into the ReduceTable are sent to the ReduceLambda for further processing via DynamoDB Streams. The responsibility of the ReduceLambda is to further combine incoming pre-aggregated messages and to update the final value in the AggregateTable.
This is done in three steps:
- The
ReduceLambdafunction is invoked with a batch of messages and reads the current state from theAggregateTable - The function re-computes the aggregate considering the given batch of pre-aggregated items
- The reduce function writes the updated values into the
AggregateTable
Note: there is only one instance of the ReduceLambda function, which is achieved by setting the reserved concurrency to 1. This is desired to avoid a potential write conflict while updating the AggregateTable. From a performance point of view, a single Lambda function instance can handle aggregation of the entire pipeline because incoming messages are already pre-aggregated by the MapLambda functions.
The final output in the AggregateTable closely resembles the Hierarchy attribute elements, and can be easily read and displayed by a front-end!
Continue on to: Connect the Pipeline