Step 2 - Load data into the new table
Now, execute a script that loads the data from the file named ./employees.csv into the table named employees.
python load_employees.py employees ./data/employees.csv
The sample employees.csv record looks like the following:
1000,Nanine Denacamp,Programmer Analyst,Development,San Francisco,CA,1981-09-30,2014-06-01,Senior Database Administrator,2014-01-25
When you ingest this data into the table, you concatenate some of the attributes, such as city_dept (example: San Francisco:Development) because you have an access pattern in the query that takes advantage of this concatenated attribute. The SK attribute is also a derived attribute. The concatenation is handled in the Python script, which assembles the record and then executes a put_item() to write the record to the table.
Output:
$ python load_employees.py employees ./data/employees.csv
employee count: 100 in 3.7393667697906494
employee count: 200 in 3.7162938117980957
...
employee count: 900 in 3.6725080013275146
employee count: 1000 in 3.6174678802490234
RowCount: 1000, Total seconds: 36.70457601547241
The output confirms that 1000 items have been inserted to the table.
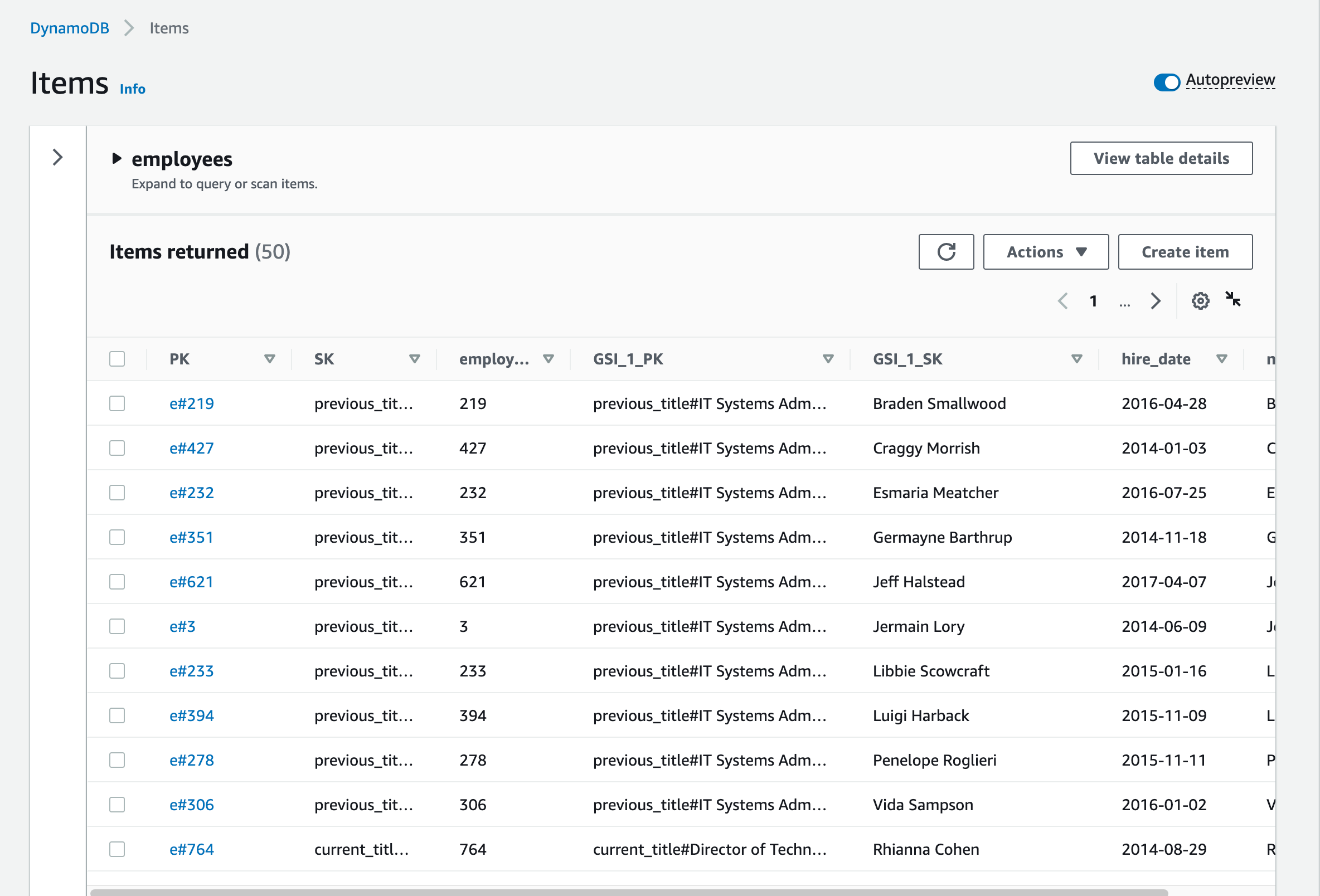
Review the employees table in the DynamoDB console (as shown in the following screenshot) by choosing the employees table and then choosing the Items menu item.
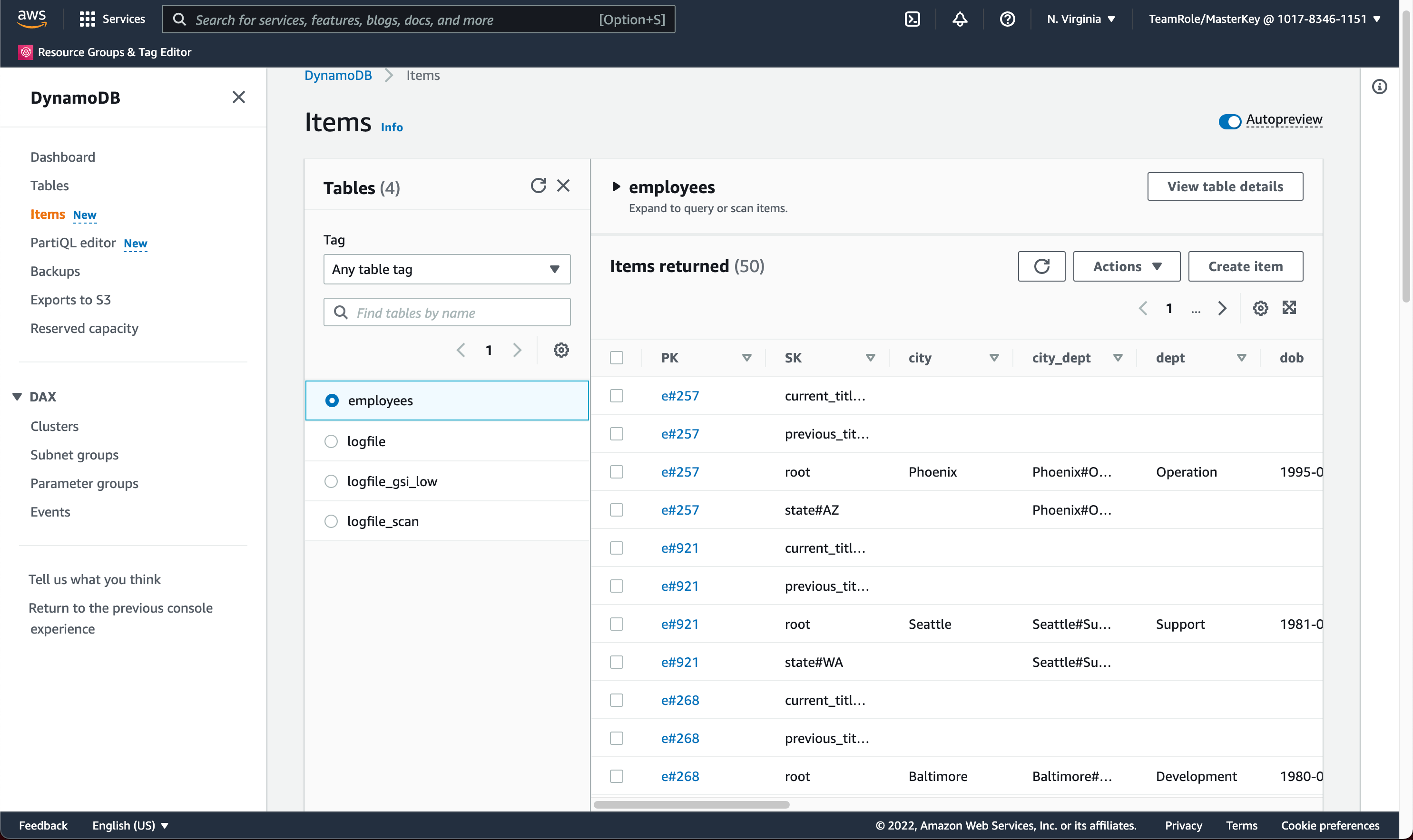
On the same page in the right pane, choose [Index] from the dropdown menu and then click Run.
Now you can see result of “Scan” operation on an overloaded global secondary index. There are many different entity types in the result set: a root, a previous title, and a current title.