Overview
Architecture
After setup, most of the components the data aggregation pipeline are already put in place for you, as shown in the diagram below. However, some of the links between neighboring components are missing or misconfigured! These connections are the crux of the problem you have to solve.
The workshop contains two labs. The objective of the first lab is to establish connections between these components and achieve end-to-end data processing, from the IncomingDataStream on the left to the AggregateTable at the end of the pipeline.
However, the pipeline you build in the first lab doesn’t ensure exactly once message processing. Therefore, establishing exactly once processing is the goal of Lab 2.
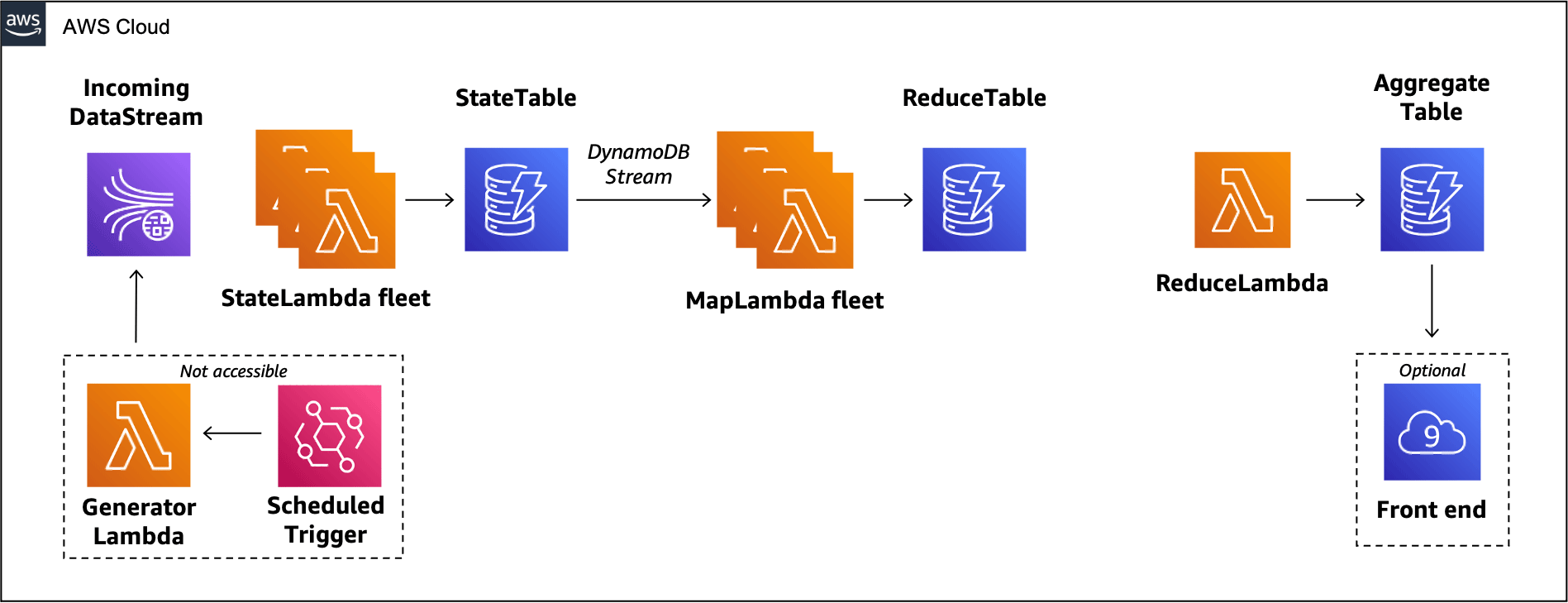
Lab 1
The diagram below outlines a set of steps that you will need to perform in order to connect all the AWS resources. The Lab 1 section will give you more information and will explain how to perform each step.
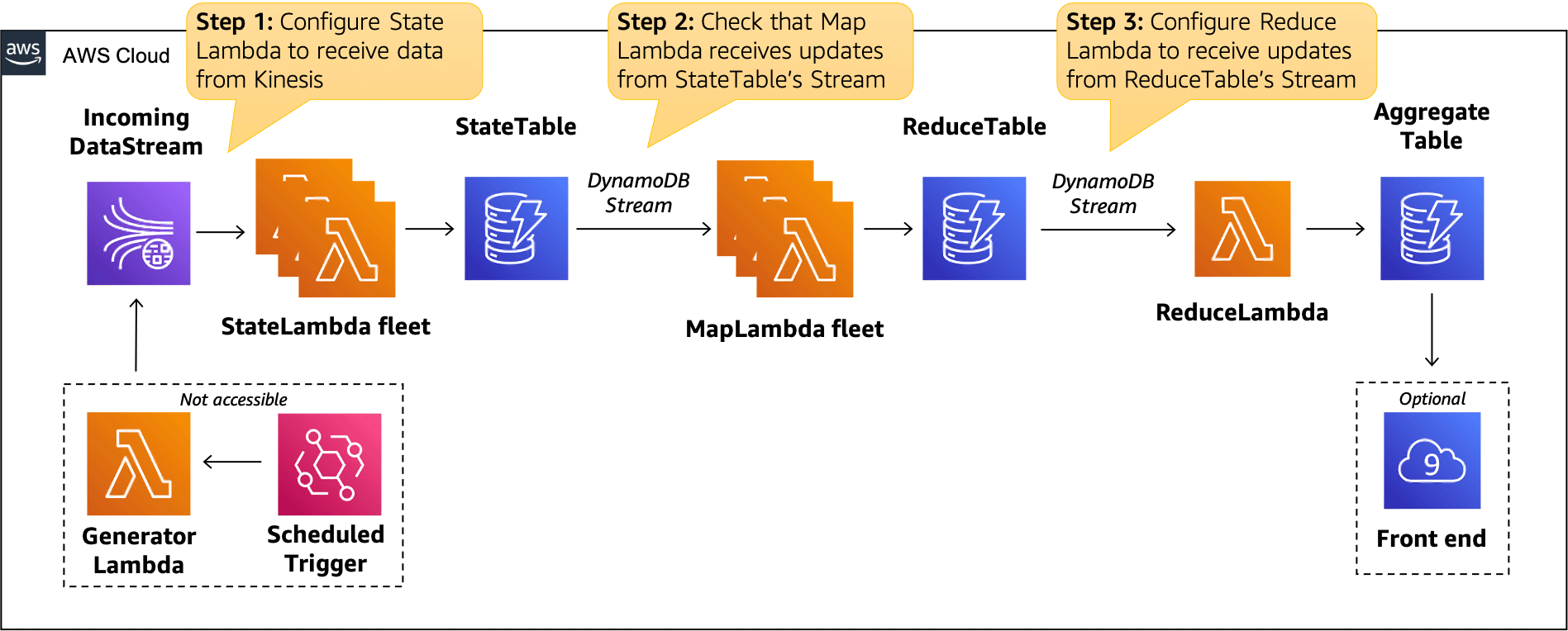
Lab 2
In Lab 2, we will enhance the pipeline to ensure exactly once processing for any ingested message. To make sure that our pipeline can withstand different failure modes and achieve exactly once message processing we will modify two Lambda functions.
The Lab 2 section will give you more information and will explain how to perform each step. 
Next steps and competition
The Pipeline deep dive with example subsection contains a detailed explanation of how data is processed in this pipeline. This information is recommended but not necessary to complete the workshop.
To make this workshop more exciting, when run at an AWS event all participants are rated on how many messages they can aggregate correctly using a scoreboard. The Game rules subsection outlines the rules of the game, and how the GeneratorLambda function ingests data into the start of the pipeline!
Continue on to: Game Rules.