Sparse Global Secondary Indexes
Tổng quan
Bảng Chỉ mục GSI Sparse được sử dụng để định vị các items chứa thuộc tính không phổ biến - đó là những thuộc tính không xuất hiện trong tất cả các item có trong bảng. Việc truy vấn các item có thuộc tính không phổ biến có thể hiệu quả hơn do số lượng item trong bảng Chỉ mục ít hơn đáng kể so với số lượng item trong bảng Cơ sở. Ngoài ra, càng ít thuộc tính chiếu từ bảng cơ sở sang bảng chỉ mục, thì lại càng ít dung lượng đọc ghi bị tiêu thụ bởi bảng chỉ mục.
Thực hành
- Thêm Chỉ mục phụ toàn cục mới vào bảng Emloyees
Bảng Chỉ mục GSI mới sẽ sử dụng thuộc tính is_manager làm partition key do không phải nhân viên nào cũng là manager và thuộc tính này không xuất hiện ở tất cả các item. Khóa này được lưu trữ dưới thuộc tính có tên GSI_2_PK. Chức danh của nhân viên được lưu trữ làm soft key GSI_2_SK.
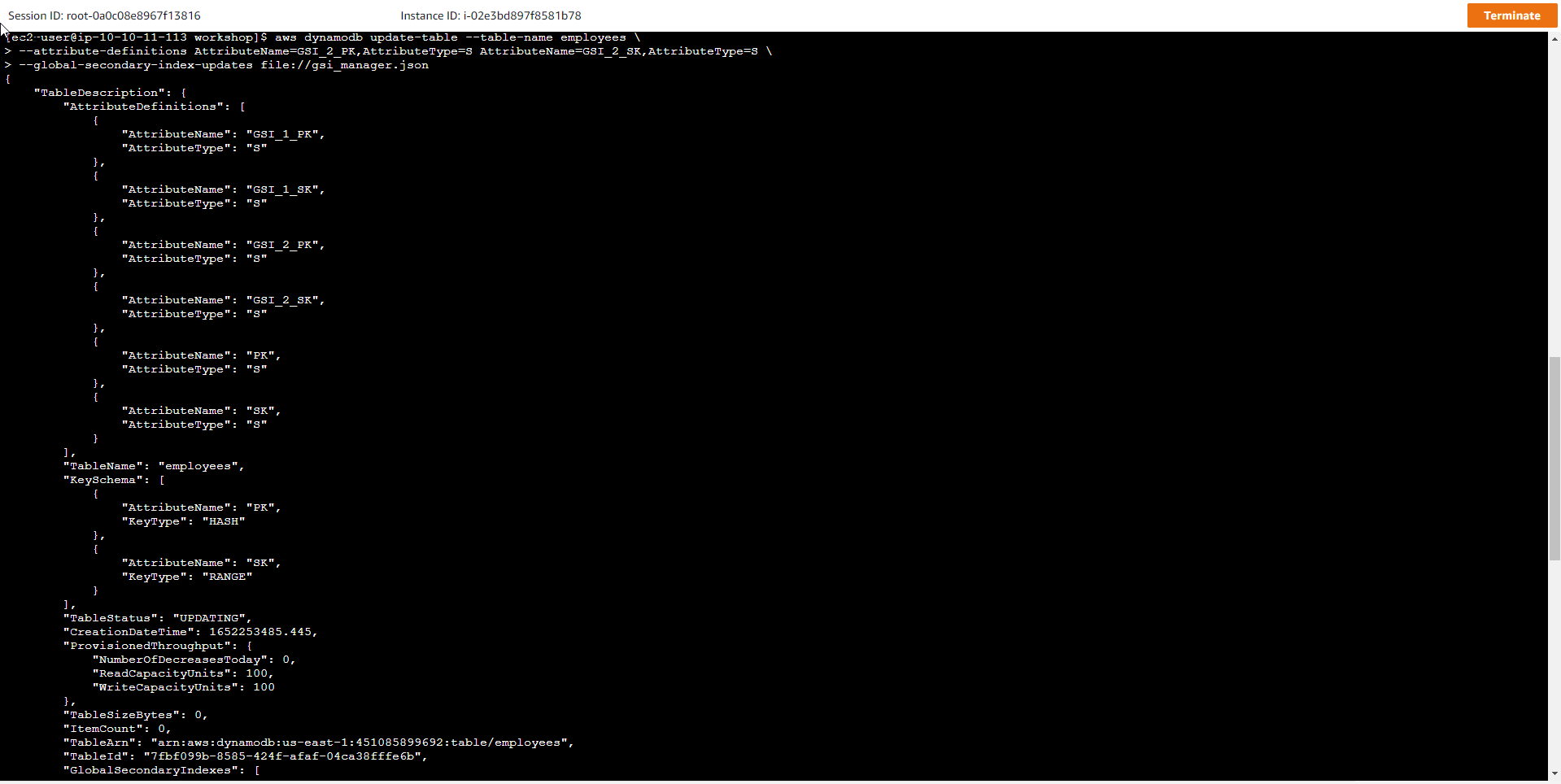
aws dynamodb update-table --table-name employees \
--attribute-definitions AttributeName=GSI_2_PK,AttributeType=S AttributeName=GSI_2_SK,AttributeType=S \
--global-secondary-index-updates file://gsi_manager.json
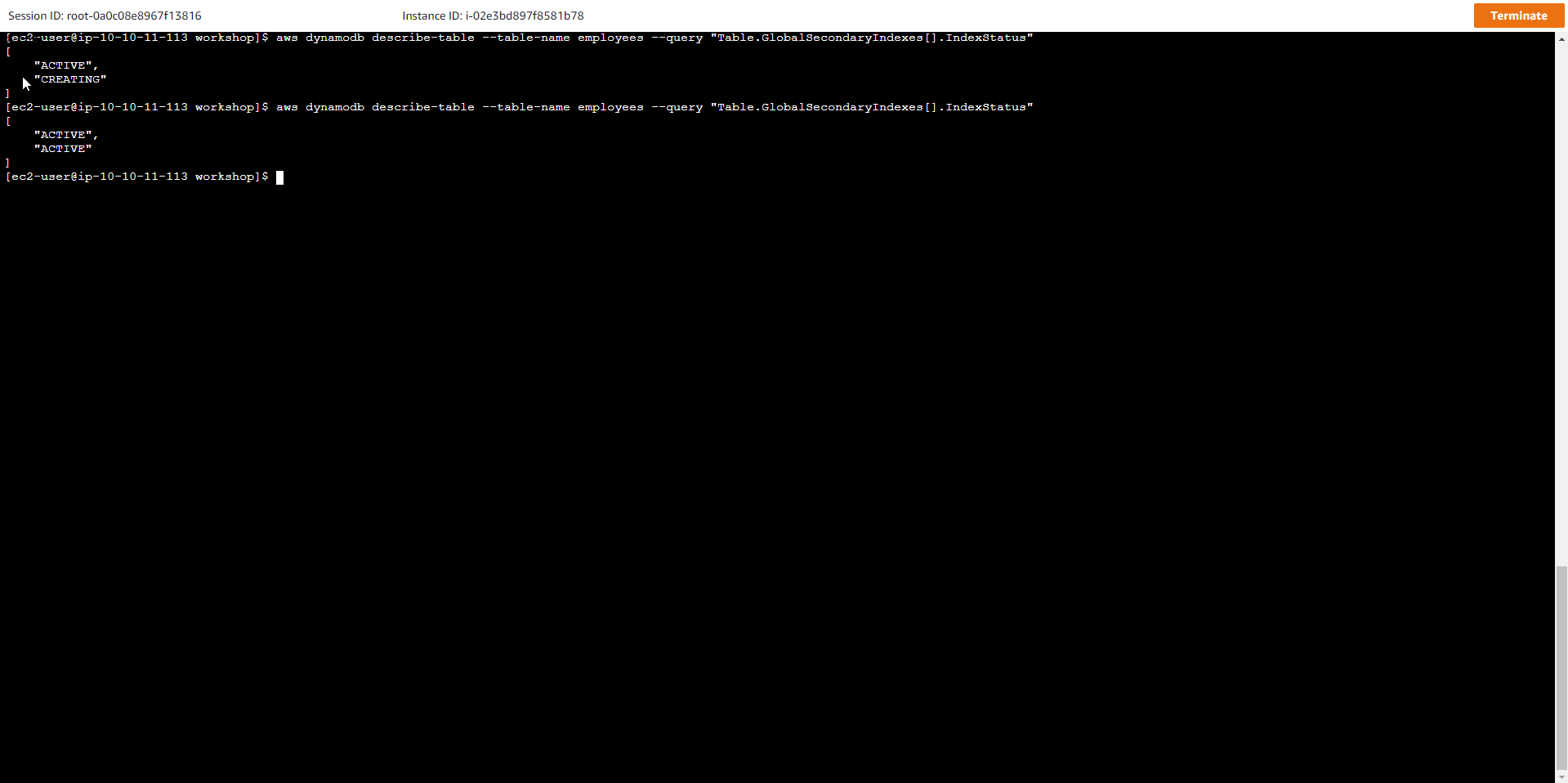
- Quá trình tạo một chỉ mục mới cho bảng sẽ mất khoảng 5 phút. Kiểm tra trạng thái bằng lệnh bên dưới. Nếu giá trị IndexStatus bằng CREATING thì bạn sẽ phải tiếp tục đợi cho tới khi nó chuyển thành ACTIVE.
aws dynamodb describe-table --table-name employees --query "Table.GlobalSecondaryIndexes[].IndexStatus"
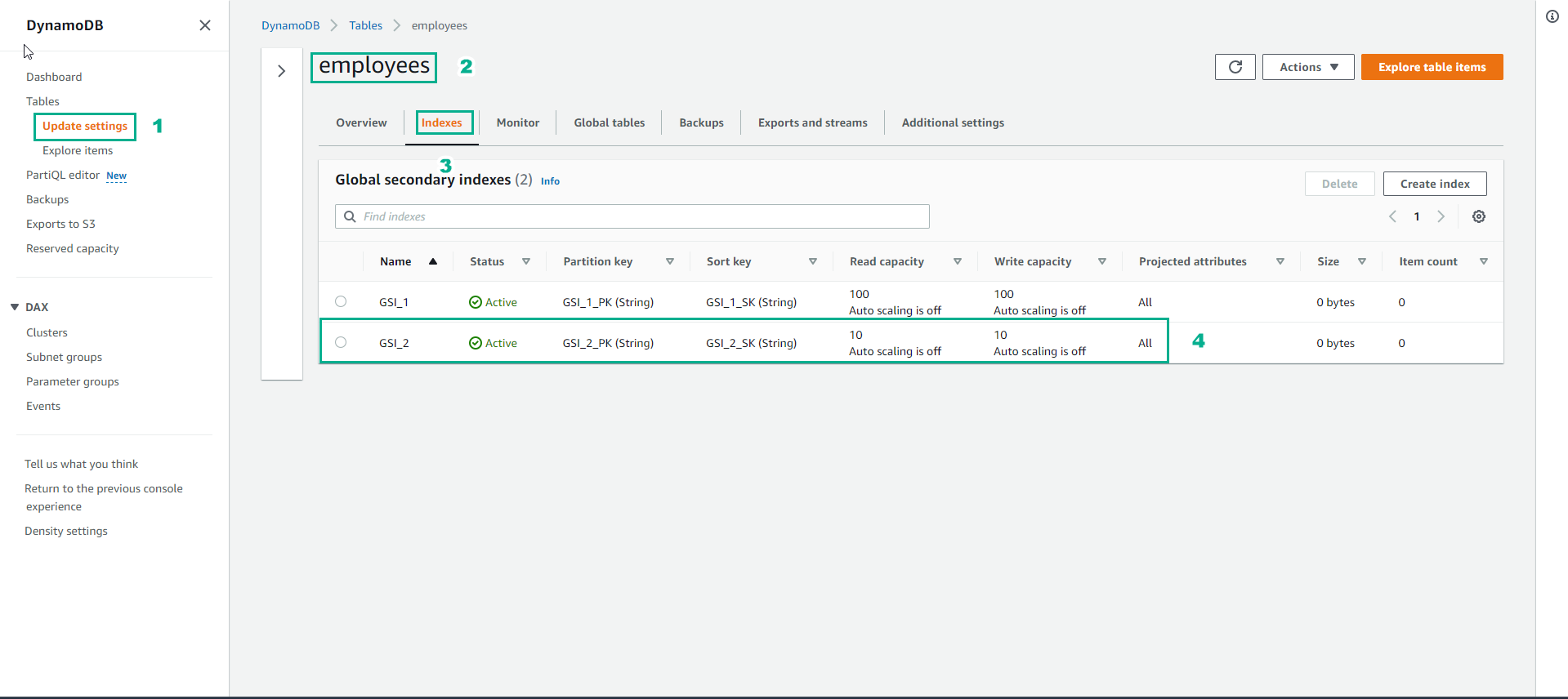
- Trong giao diện DynamoDB
- Chọn Table
- Chọn bảng employees
- Chọn Indexes
- GSI_2 đã khởi tạo hoàn thành và trạng thái Active
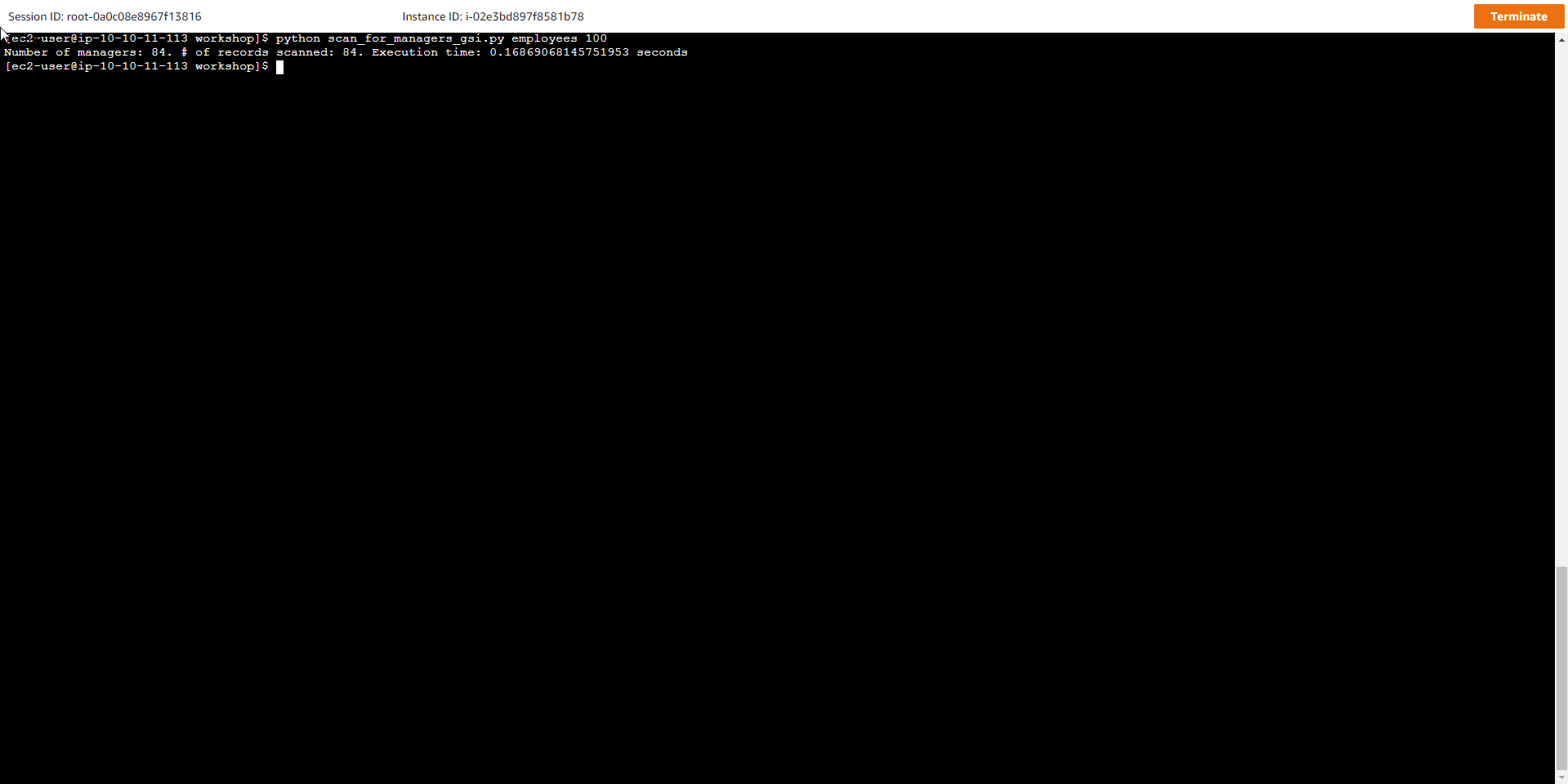
- Quét bảng để tìm nhân viên là Manager - Không sử dụng Chỉ mục rời rạc
Sparse index sẽ giúp cắt nhỏ dữ liệu của bạn ra thành nhiều phần nhỏ hơn với các chỉ mục tương ứng để việc Quét dữ liệu hoặc API truy vấn hoạt động hiệu quả hơn. Thay vì quét toàn bộ dữ liệu trong một bảng Cơ sở DynamoDB thì bạn có thể tạo ra một chỉ mục để chỉ giữ một phần thông tin thuận tiện cho việc truy vấn và tìm kiếm.
Để nắm rõ hơn về cách tách bảng Cở sở ra thành các bảng nhỏ hơn với Sparse Index, bạn có thể tham khảo bài viết Take Advantage of Sparse Indexes
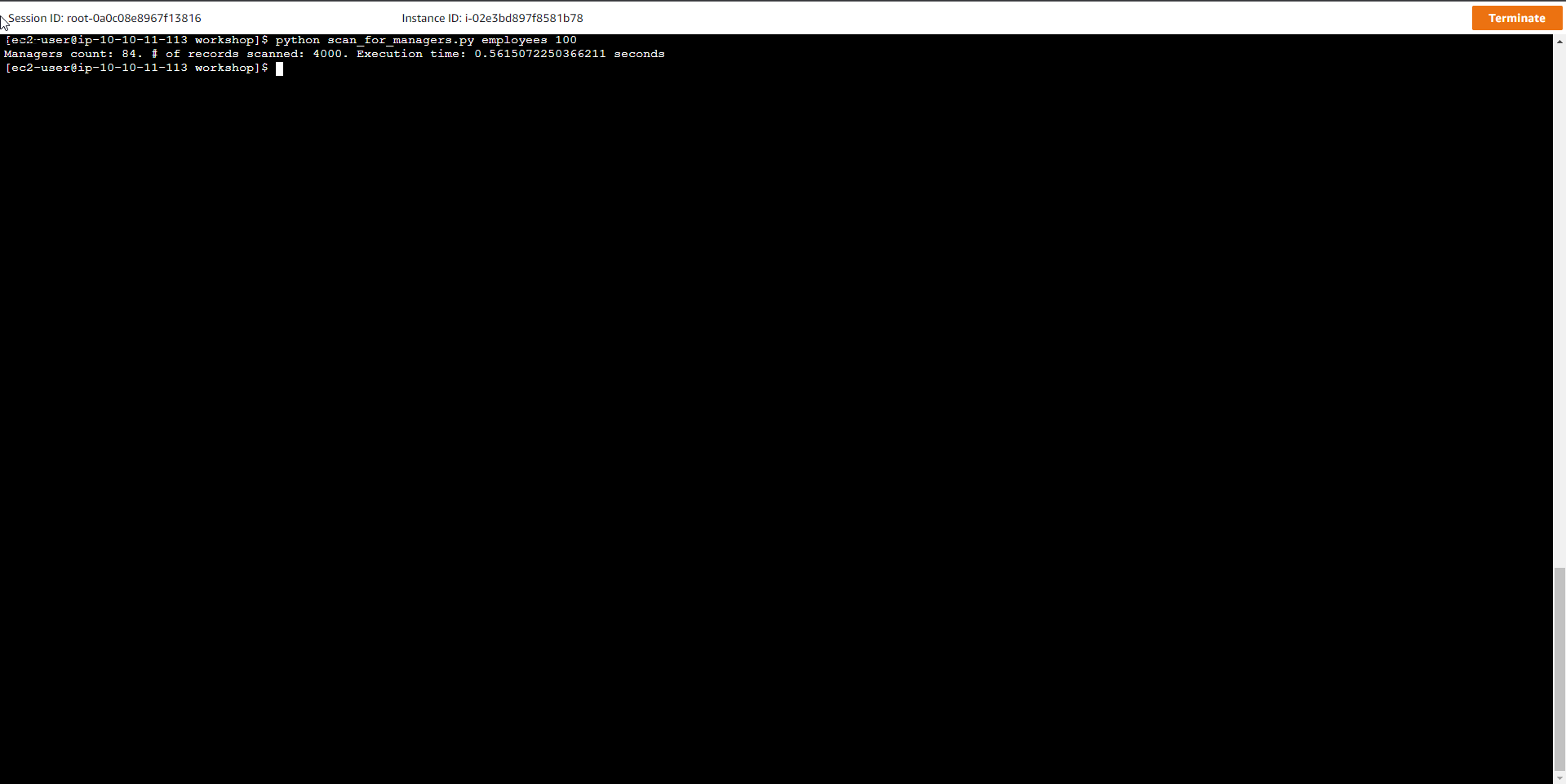
Đầu tiên, chúng ta sẽ quét bảng dữ liệu để tìm kiếm tất cả các Manager mà không sử dụng bảng chỉ mục.
python scan_for_managers.py employees 100
Trong đó, employees là tên bảng, 100 là số lượng item mỗi lần quét. Kết quả của thao tác quét tương tự như sau:
Managers count: 84. # of records scanned: 4000. Execution time: 0.596132993698 seconds
- Quét bảng để tìm nhân viên là Manager - Sử dụng Chỉ mục rời rạc
Sử dụng bảng chỉ mục Sparse đã tạo ở bước 1 để thực hiện quét dữ liệu bảng Employees. Đoạn code sử dụng Sparse index mô tả trong script chạy lệnh quét như sau:
response = table.scan(
Limit=pageSize,
IndexName='GSI_2'
)
Thực thi lệnh quét dữ liệu
python scan_for_managers_gsi.py employees 100
Trong đó, employees là tên bảng, 100 là số lượng item của mỗi lần quét. Kết quả cho ta thấy số lượng item được quét và thời gian thực hiện nhỏ hơn rất nhiều so với trường hợp không sử dụng Sparse index
Number of managers: 84. # of records scanned: 84. Execution time: 0.287754058838 seconds