Quét dữ liệu bảng kiểu tuần tự và song song
Quét dữ liệu bảng kiểu tuần tự và song song
Tổng quan
Mặc dù DynamoDB phân tán các item lên nhiều phân vùng vật lý khác nhau, nhưng thao tác Quét chỉ có thể đọc được một phân vùng tại một thời điểm. Do vậy thông lượng của thao tác Quét bị hạn chế bởi thông lượng tối đa của một phân vùng.
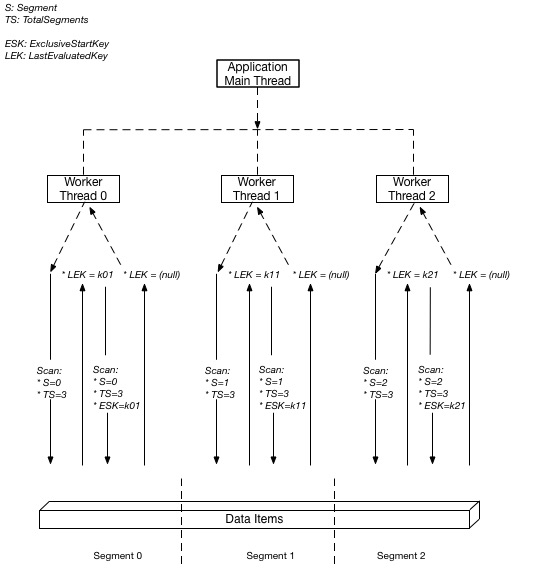
Để tối đa hóa thao tác Quét dữ liệu ở mức bảng, ta sử dụng Quét Song song để chia một bảng Cơ sở logic (hoặc bảng Chỉ mục GSI) thành nhiều phân đoạn logic, và sử dụng nhiều trình xử lý ứng dụng để quét song song các phân đoạn logic này.
Mỗi trình xử lý ứng dụng worker có thể là một luồng trong các ngôn ngữ lập trình hỗ trợ xử lý đa luồng hoặc có thể là một tiến trình của hệ điều hành.
Sơ đồ bên dưới mô tả cách một ứng dụng đa luồng thực hiện Quét Song song với ba luồng xử lý ứng dụng. Ứng dụng tạo ra ba luồng và mỗi luồng đưa ra yêu cầu Quét rồi quét những phân đoạn mà nó đã được chỉ định. Dữ liệu thu được sau lệnh quét được trả về ứng luồng ứng dụng chính với kích thước không vượt quá 1 MB.
Thực hành
- Bước đầu tiên chúng ta thực thi một lệnh Quét Tuần tự để tính tổng số byte đã gửi cho các bản ghi có mã phản hồi <> 200. Lệnh Quét có thể kết hợp với biểu thức bộ lọc để lọc ra các bản ghi không liên quan. Sau đó, trình xử lý ứng dụng sẽ tính tổng số byte đã gửi của tất cả các bản ghi có mã phản hồi <> 200.
- Ở đây chúng tôi đã chuẩn bị sẵn file scan_logfile_simple.py, bao gồm lệnh chạy Quét với một biểu thức bộ lọc rồi thực hiện tính tổng các byte đã được gửi.
Nội dung mã lệnh thực hiện quét dữ liệu bảng
fe = "responsecode <> :f"
eav = {":f": 200}
response = table.scan(
FilterExpression=fe,
ExpressionAttributeValues=eav,
Limit=pageSize,
ProjectionExpression='bytessent')
Số item mà thao tác Quét có thể đọc được tùy thuộc vào số item lớn nhất được đặt (nếu sử dụng tham số Limit) hoặc tối đa 1 MB dữ liệu, sau đó áp dụng bất kỳ bộ lọc nào cho kết quả bằng cách sử dụng FilterExpression. Nếu tổng số item được quét vượt quá mức tối đa được đặt bởi tham số Limit hoặc vượt quá giới hạn kích thước tập dữ liệu là 1 MB, quá trình quét sẽ dừng lại và kết quả được trả về cho user dưới dạng giá trị LastEvaluatedKey.
Trong đoạn mã bên dưới, giá trị LastEvaluatedKey được chuyển đến phương thức Quét qua tham số ExclusiveStartKey.
while 'LastEvaluatedKey' in response:
response = table.scan(
FilterExpression=fe,
ExpressionAttributeValues=eav,
Limit=pageSize,
ExclusiveStartKey=response['LastEvaluatedKey'],
ProjectionExpression='bytessent')
for i in response['Items']:
totalbytessent += i['bytessent']
Cho tới khi những bản ghi cuối cùng được trả về thì giá trị tham số LastEvaluatedKey không còn là một phần của thông tin phản hồi nữa, đồng nghĩa tiến trình scan kết thúc.
Nào, bây giờ chúng ta hãy cùng thực thi mã lệnh như bên dưới
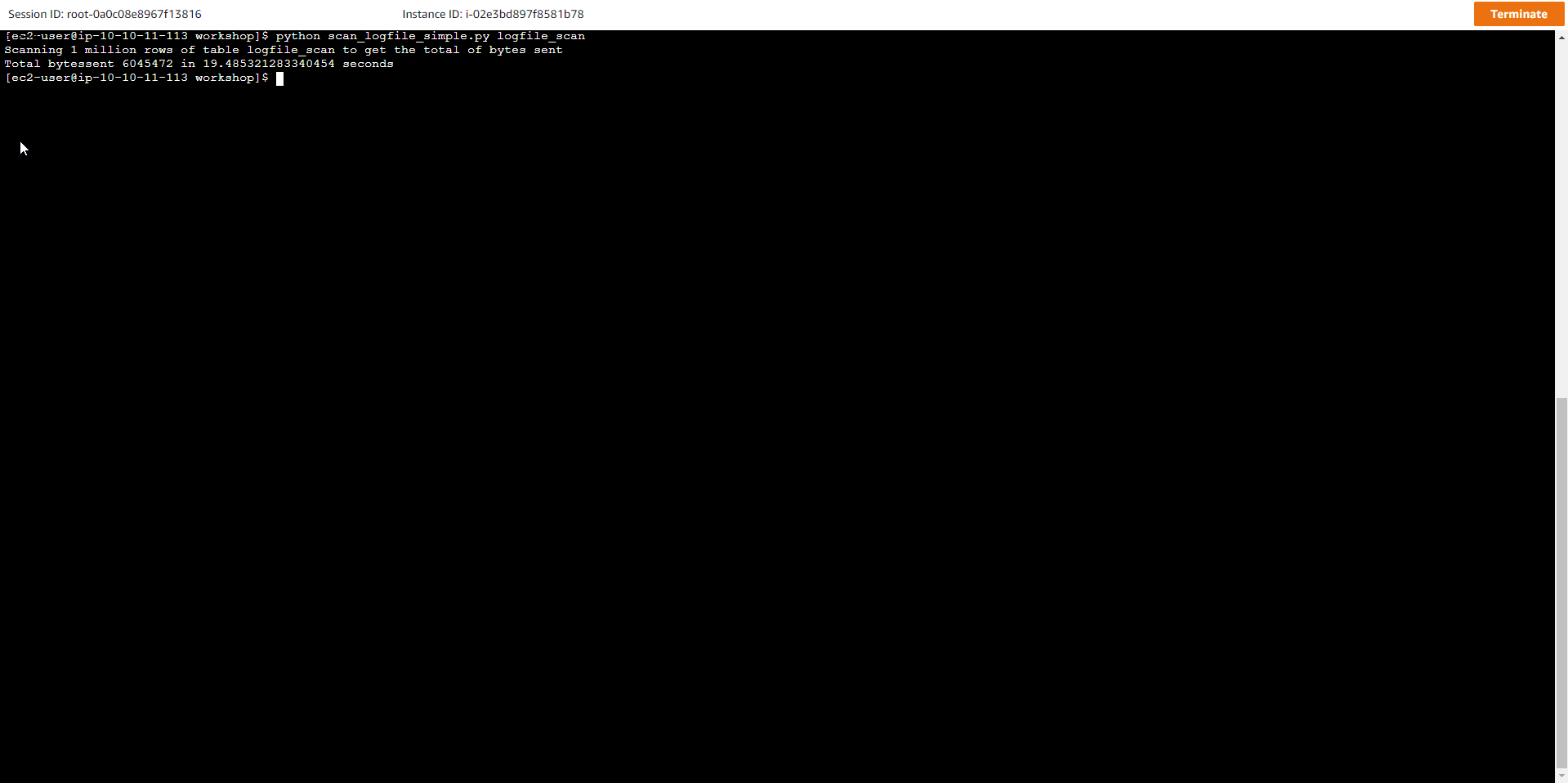
python scan_logfile_simple.py logfile_scan
Trong đó, tên bảng là logfile_scan Kết quả đầu ra tương tự như sau:
Scanning 1 million rows of table logfile_scan to get the total of bytes sent
Total bytessent 6054250 in 16.325594425201416 seconds
Lưu lại thời gian hoàn thành với Scan kiểu Tuần tự. Sau đó chúng ta cùng chuyển qua bước tiếp theotheo.
- Thực hành Quét Song song
-
Để thực hiện Quét song song, mỗi trình xử lý ứng dụng phải đưa ra yêu cầu Quét của riêng nó với các tham số sau:
-
Segment: Mỗi phân đoạn được quét bởi một trình xử lý ứng dụng cụ thể do vậy mỗi Phân đoạn nên có giá trị đại diện khác nha
-
TotalSegments: Tổng số phân đoạn trong quá trình quét song song. Giá trị này phải bằng với số lượng trình xử lý mà ứng dụng sẽ sử dụng.
Nội dung đoạn mã thực hiện quét song song trong file scan_logfile_parallel.py
fe = "responsecode <> :f"
eav = {":f": 200}
response = table.scan(
FilterExpression=fe,
ExpressionAttributeValues=eav,
Limit=pageSize,
TotalSegments=totalsegments,
Segment=threadsegment,
ProjectionExpression='bytessent'
)
Sau lần quét đầu tiên, tiến trình scan tiếp tục cho tới khi giá trị tham số LastEvaluatedKey bằng null.
while 'LastEvaluatedKey' in response:
response = table.scan(
FilterExpression=fe,
ExpressionAttributeValues=eav,
Limit=pageSize,
TotalSegments=totalsegments,
Segment=threadsegment,
ExclusiveStartKey=response['LastEvaluatedKey'],
ProjectionExpression='bytessent')
for i in response['Items']:
totalbytessent += i['bytessent']
Thực thi script để bắt đầu thực hiện Quét Song song
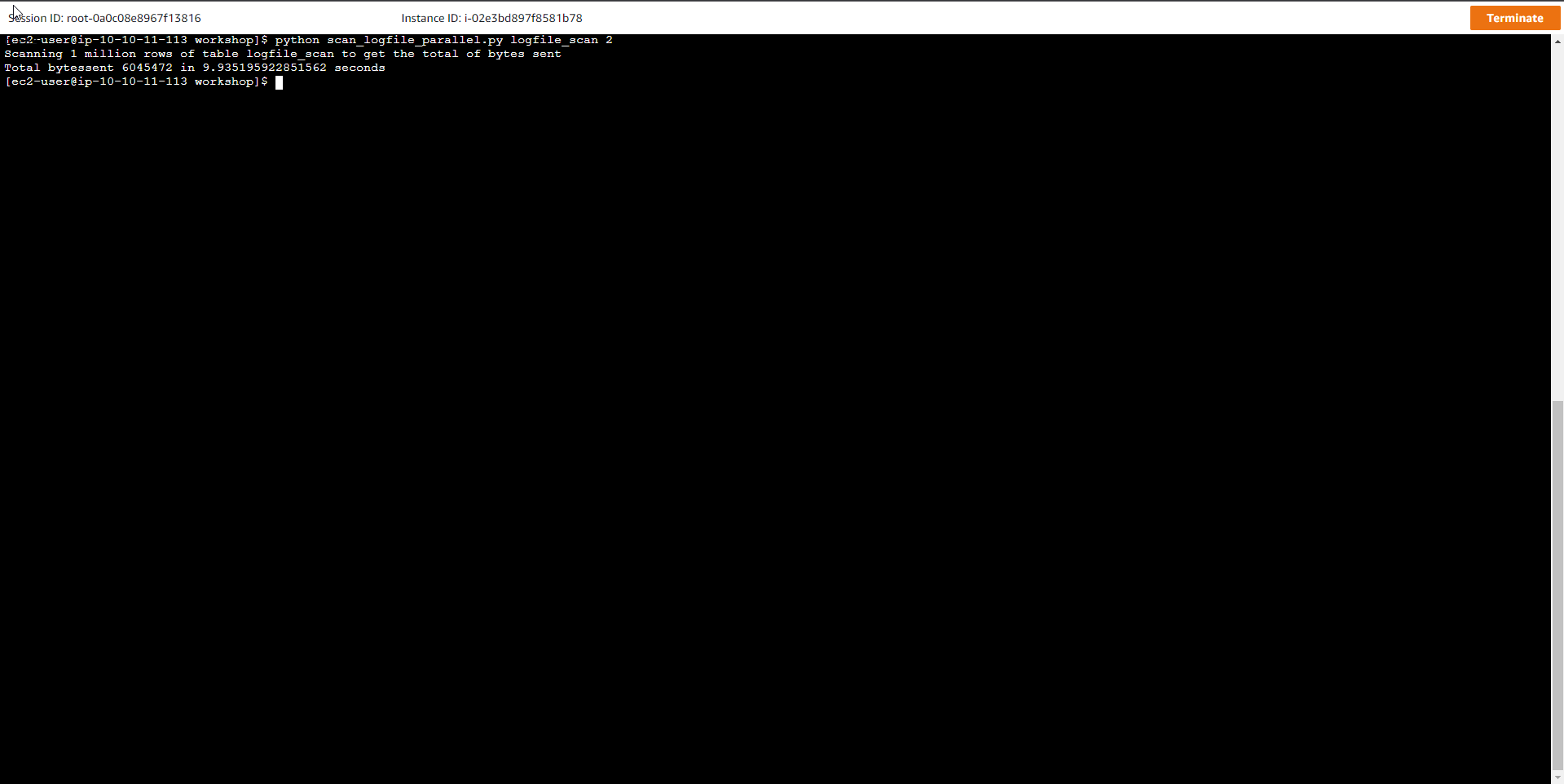
python scan_logfile_parallel.py logfile_scan 2
Trong đó, tên bảng là logfile_scan, số luồng hay số trình xử lý là 2.
Kết quả sau lệnh quét là thời gian quét song song ngắn hơn khá nhiều so với kiểu quét tuần tự. Khác biệt có thể sẽ còn lớn hơn nếu bảng dữ liệu chứa số lượng item lớn hơn.
Scanning 1 million rows of the `logfile_scan` table to get the total of bytes sent
Total bytessent 6054250 in 8.544446229934692 seconds
Kết luận
-
Trong bài thực hành này, chúng ta đã cùng nhau tìm hiểu và sử dụng hai phương pháp quét bảng DynamoDB: Tuần tự và Song song, để đọc các item từ một bảng hoặc bảng chỉ mục GSI.
-
Thao tác Quét là một thao tác tiêu tốn một lượng lớn tài nguyên dung lượng, do vậy nên tránh sử dụng thao tác này.
-
Nó chỉ hợp lý khi ta thực hiện quét một bảng nhỏ hoặc thao tác Quét là bất khả kháng(chẳng hạn như trích xuất hàng loạt dữ liệu).
-
Tuy nhiên, theo nguyên tắc chung thì bạn nên thiết kế các ứng dụng của mình để tránh thực hiện quét.