DynamoDB Capacity Units và Partitioning
DynamoDB Capacity Units và Partitioning
Lưu ý: trình duyệt đối với Windows như Chrome, Firefox, hoặc Edge phải là phiên bản mới nhất; cũng như vậy với Apple Safari trên macOS
Trong bài thực hành đầu tiên này, bạn sẽ load dữ liệu vào các bảng DynamoDB với những giá trị write/read capacity khác nhau và so sánh thời gian load giữa các tập dữ liệu khác nhau.
Ở lần thử thứ nhất, ta nạp một tập dữ liệu nhỏ vào bảng rồi nhanh chóng lưu lại thời gian thực hiện. Tiếp theo, ta load tập dữ liệu lớn hơn vào một bảng để mô phỏng tình huống ngoại lệ khiến tắc nghẽn truyền tải dữ liệu. Cuối cùng, ta mô phỏng áp lực ngược lại của GSI lên một bảng cách tạo một bảng có capacity cao và một GSI chỉ có 1 write capacity unit (WCU).
Cũng trong bài thực hành này, ta sẽ sử dụng dữ liệu nhật ký truy cập máy chủ Web mẫu, tương tự như dữ liệu nhật ký máy chủ web được tạo bởi Apache.
Trước khi bắt đầu bài thực hành, chúng tôi muốn được cùng các bạn điểm qua một số kiến thức quan trọng mà bạn cần phải nắm liên quan tới CSDL No-SQL DynamoDB. Trong DynamoDB, table, item, attribute là những thành phần chính mà ta thường xuyên làm việc cùng. Bảng (table) là một tập hợp của các item, và mỗi item là một tập hợp của các thuộc tính (attribute).
DynamoDB sử dụng các Primary Key (PK) để phân biệt các item trong một bảng với nhau, còn secondary indexe thì giúp tăng thêm tính linh hoạt cho các truy vấn. Bạn có thể sử dụng DynamoDB Stream để capture những sự kiện dẫn tới thay đổi của bảng dữ liệu DynamoDB.
Khóa Chính - Primary Key
Khóa chính có 2 loại là: Partition key và Partition key + Sort key
Partition key: là loại khóa chỉ gồm 1 thuộc tính. DynamoDB sử dụng giá trị của thuộc tính mà được thiết lập làm Partition key để làm thông tin đầu vào cho hash function. - - - Kết quả của hash function sẽ giúp xác định phân vùng, nơi chứa item tương ứng.
- Mỗi bảng chỉ có duy nhất 1 partition key, và không tồn tại 2 giá trị partition key giống nhau trong cùng một bảng.
- Ví dụ bảng People, Primary Key có partition key là PersonID, bạn có thể lấy thông tin của bất cứ item nào miễn là bạn có giá trị PersonID tương ứng với item đó. Trường hợp này Primary key chính là Partition key.

Partition key + Sort key: là loại khóa kết hợp của 2 thuộc tính khác nhau của 1 bảng. Thuộc tính đầu tiên đóng vai trò là Partition key, và thuộc tính thứ 2 đóng vai trò là Sort key.
- DynamoDB vẫn sử dụng giá trị của partition key làm đầu vào cho hash function. Kết quả đầu ra của hash function được dùng để xác định phân vùng chứa các item tương ứng. Đồng thời các item này cũng được lưu trữ cùng một vị trí và được sắp xếp dựa theo giá trị của sort key.
- Trong một bảng mà có cả partition key và sort key, thì việc các giá trị của partition key trùng nhau là hoàn toàn bình thường, tuy nhiên các item này nhất định phải có giá trị sort key khác nhau để phân biệt chúng với nhau.
- Ví dụ bảng Music, Primary key bao gồm partition key là Artist và sort key là SongTitle. Bạn chỉ có thể lấy được thông tin của item khi và chỉ khi cung cấp đủ 2 thông tin Artist và SongTitle.
- Khóa Chính kết hợp kiểu này thường được sử dụng khi ta muốn bổ sung thêm tính linh hoạt cho việc truy vấn dữ liệu. Ví dụ trường hợp ta chỉ muốn lấy danh sách các bài hát của một Artist cụ thể nào đó, thì ta chỉ cần cung cấp giá trị của partition key tương ứng với giá trị của thuộc tính Artist, cùng với một dải giá trị của thuộc tính SongTitle.

Partition key còn được gọi là thuộc tính Hash - do partition key được sử dụng làm đầu vào cho hash function. Sort key còn được gọi là thuộc tính Range - do cách lưu trữ các item có giá trị partition key giống nhau và sắp xếp chúng dựa theo giá trị sort key.
- Thuộc tính mà được sử dụng làm Primary key phải có giá trị vô hướng. Những loại dữ liệu mà Khóa Chính được phép sử dụng là string, number, hoặc binary.
Chỉ mục Thứ cấp - Secondary Indexes
-
Bạn có thể tạo một hoặc nhiều Chỉ mục Thứ cấp cho một bảng DynamoDB.
-
Chỉ mục Thứ cấp cho phép bạn truy vấn dữ liệu trong bảng sử dụng khóa thay thế, ngoài các truy vấn sử dụng khóa chính.
-
Việc sử dụng Chỉ mục là không bắt buộc trong DynamoDB, tuy nhiên nếu biết cách sử dụng nó có thể đem lại tính linh hoạt cho các lệnh truy vấn dữ liệu.
-
Sau khi bảng Chỉ mục được xác định, bạn có thể đọc dữ liệu từ đó giống như đọc trên bảng DynamoDB ban đầu.
-
DynamoDB hỗ trợ 2 loại Chỉ mục Thứ cấp đó là:
-
Chỉ mục Thứ cấp Toàn cục: Chỉ mục với cặp giá trị Partition key và Sort key phải là khác biệt giữa các bảng dữ liệu
-
Chỉ mục Thứ cấp Cục bộ: Chỉ mục với Partition key có thể giống nhau trên cùng 1 bảng, nhưng bắt buộc giá trị Sort key phải khác nhau
-
-
Mỗi bảng DynamoDB được phép có 20 GSI (mặc định) và 5 chỉ mục thứ cấp cục bộ.
-
Trong ví dụ bảng Music, bạn có thể truy vấn dữ liệu với partition key là Artist hoặc truy vấn với cặp (partition key + sort key) là Artist + SongTitle. Những sẽ thế nào nếu bạn muốn truy vấn dữ liệu bằng thuộc tính Genre và AlbumTitle. Để làm được điều này, bạn phải tạo một Chỉ mục bao gồm 2 thuộc tính Genre và AlbumTitle, rồi thực hiện truy vấn Bảng Chỉ mục giống như khi truy vấn trên bảng Music ban đầu.
-
Biểu đồ sau đây biểu diễn cách một Bảng Chỉ mục có tên GenreAlbumTitle được tạo ra. Trong Bảng Chỉ mục thì Genre đóng vai trò là Partition key, còn AlbumTitle đóng vai trò là Sort key.

Một vài lưu ý đối với bảng Chỉ mục GenreAlbumTitle:
-
Mỗi bảng Chỉ mục GSI thuộc về một bảng dữ liệu được gọi là bảng Cơ sở (base table). Theo như ví dụ phía trên, bảng Music là bảng Cơ sở đối với bảng Chỉ mục GenreAlbumTitle.
-
DynamoDB bảo trì bảng Chỉ mục một cách tự động. Mỗi khi ta thêm, sửa hoặc xóa item khỏi bảng dữ liệu, DynamoDB sẽ tự động thêm, sửa hoặc xóa item tương ứng trong bảng Chỉ mục thuộc bảng Cơ sở của nó.
-
Khi tạo một Chỉ mục, bạn phải chỉ rõ những thuộc tính nào sẽ được sao chép, hoặc được chiếu từ bảng Cơ sở sang bảng Chỉ mục. Ở mức tối thiểu, DynamoDB sẽ chiếu các thuộc tính đóng vai trò là Khóa từ bảng Cơ sở sang bảng Chỉ mục. Trong ví dụ trên, chỉ có những thuộc tính đóng vai trò là Khóa trong bảng Music như Artist (Partition key), SongTitle (Sort key) là được chiếu sang bảng Chỉ mục GenreAlbumTitle.
Bạn có thể truy vấn trên bảng Chỉ mục GenreAlbumTitle để tìm tất cả album của một thể loại nhạc cụ thể (ví dụ như Rock albums). Bạn cũng có thể truy vấn để tìm tất cả các albums thuộc một thể loại nhạc cụ thể mà có tiêu đề album cụ thể (ví dụ, tất cả Country albums với tiêu đề bắt đầu bằng chữ cái H).
DynamoDB Stream
DynamoDB Streams là một tính năng tùy chọn giúp ghi lại lịch sử các sự kiện thay đổi dữ liệu trong bảng DynamoDB. Dữ liệu về các sự kiện này được lưu vào luồng dữ liệu riêng theo thời gian gần thực và theo thứ tự xảy ra sự kiện. Mỗi sự kiện tương ứng với một bản ghi trong luồng dữ liệu. Khi bảng đã được bật luồng, DynamoDB Streams sẽ ghi lại thông tin vồ luồng khi có một trong các sự kiện sau đây xảy ra:
-
Một item mới được thêm vào bảng: Luồng capture lại nội dung item mới, bao gồm các thuộc tính của nó.
-
Một item được cập nhật: Luồng ghi lại giá trị của các thuộc tính của item trạng thái “trước” và “sau” thay đổi.
-
Một item bị xóa khỏi bảng: Luồng ghi lại nội dung item trước khi bị xóa.
Mỗi bản ghi trong luồng chứa các thông tin bao gồm tên bảng, thời gian xảy ra sự kiện và các siêu dữ liệu khác. Thời gian tồn tại của một bản ghi luồng là 24 giờ; sau đó, chúng sẽ tự động bị xóa khỏi luồng.
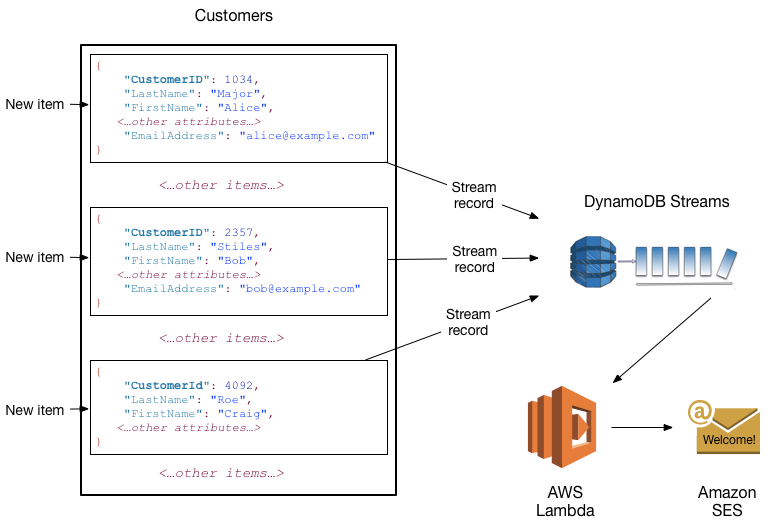
Bạn có thể sử dụng DynamoDB Stream cùng với AWS Lambda để tạo một trigger—code chạy tự động mỗi khi có một sự kiện bị ghi lại thông tin vào luồng. Ví dụ: hãy xem xét bảng Customers dưới đây, nội dung là thông tin khách hàng của một công ty. Giả sử bạn muốn gửi một email “welcome” đến từng khách hàng mới,đầu tiên phải bật luồng trên bảng đó, rồi liên kết luồng với một hàm Lambda. Bất cứ khi nào có bản ghi mới xuất hiện, thông tin item mới được đưa vào luồng, hàm Lambda sẽ xử lý các item mới đó. Đối với bất kỳ item mới nào có thuộc tính EmailAddress, hàm Lambda sẽ gọi tới Dịch vụ Amazon Simple Email Service (Amazon SES) để gửi email.
Tiếp theo đây, chúng ta sẽ cùng nhau đi vào nội dung chính của bài workshop, đó là những bài thực hành áp dụng kiến trúc nâng cao có sử dụng DynamoDB.
- Khởi tạo bảng DynamoDB. Chạy lệnh tạo một bảng DynamoDB mới có tên logfile:
aws dynamodb create-table --table-name logfile \
--attribute-definitions AttributeName=PK,AttributeType=S AttributeName=GSI_1_PK,AttributeType=S \
--key-schema AttributeName=PK,KeyType=HASH \
--provisioned-throughput ReadCapacityUnits=5,WriteCapacityUnits=5 \
--tags Key=workshop-design-patterns,Value=targeted-for-cleanup \
--global-secondary-indexes "IndexName=GSI_1,\
KeySchema=[{AttributeName=GSI_1_PK,KeyType=HASH}],\
Projection={ProjectionType=INCLUDE,NonKeyAttributes=['bytessent']},\
ProvisionedThroughput={ReadCapacityUnits=5,WriteCapacityUnits=5}"
Cấu trúc bảng mới bao gồm các thành phần sau:
-
Key schema: HASH (partition key)
-
Table read capacity units (RCUs) = 5
-
Table write capacity units (WCUs) = 5
-
Global secondary index (GSI): GSI_1 (5 RCUs, 5 WCUs) - Cho phép truy vấn theo IP address của máy host.
| Tên Thuộc tính (Loại) | Mô tả | Trường hợp Sử dụng | Ví dụ | |
|---|---|---|---|---|
| PK (STRING) | Partition key | Lưu giá trị request id phục vụ công tác kiểm tra nhật kí truy cập | request#104009 | |
| GSI_1_PK (STRING) | GSI 1 partition key | Thông tin về request, một địa chỉ IPv4 | host#66.249.67.3 |
Thuộc tính đặc biệt là những thuộc tính mà đã được thiết lập làm Khóa Chính của bảng Cơ sở hoặc của bảng Chỉ mục GSI. Các bảng Chỉ mục GSI cũng có các khóa chính giống như bảng Cơ sở của nó.
Trong DynamoDB, partition key còn được gọi với tên là hash key do giá trị của partition key được dùng là đầu vào cho hash function của bảng DynamoDB, còn sort key còn được gọi là range key do khóa này được dùng để sắp xếp lại một tập các item có cùng giá trị partition key.
Các DynamoDB API sử dụng thuật ngữ hash và range, trong khi các tài liệu của AWS sử dụng thuật ngữ partition và sort. Tuy nhiên bất kể thuật ngữ nào, hai khóa này cũng sẽ cùng nhau tạo thành khóa chính Primary key.
- Chạy lệnh sau đây và chờ cho tới khi trạng thái của bảng trở thành ACTIVE:
aws dynamodb wait table-exists --table-name logfile
- Hoặc chỉ để kiểm tra trạng thái bảng, ta dùng lệnh:
aws dynamodb describe-table --table-name logfile --query "Table.TableStatus"
- Trong giao diện AWS DynamoDB
- Chọn Table
- Xem trạng thái bảng logfile là Active thì tạo bảng thành công
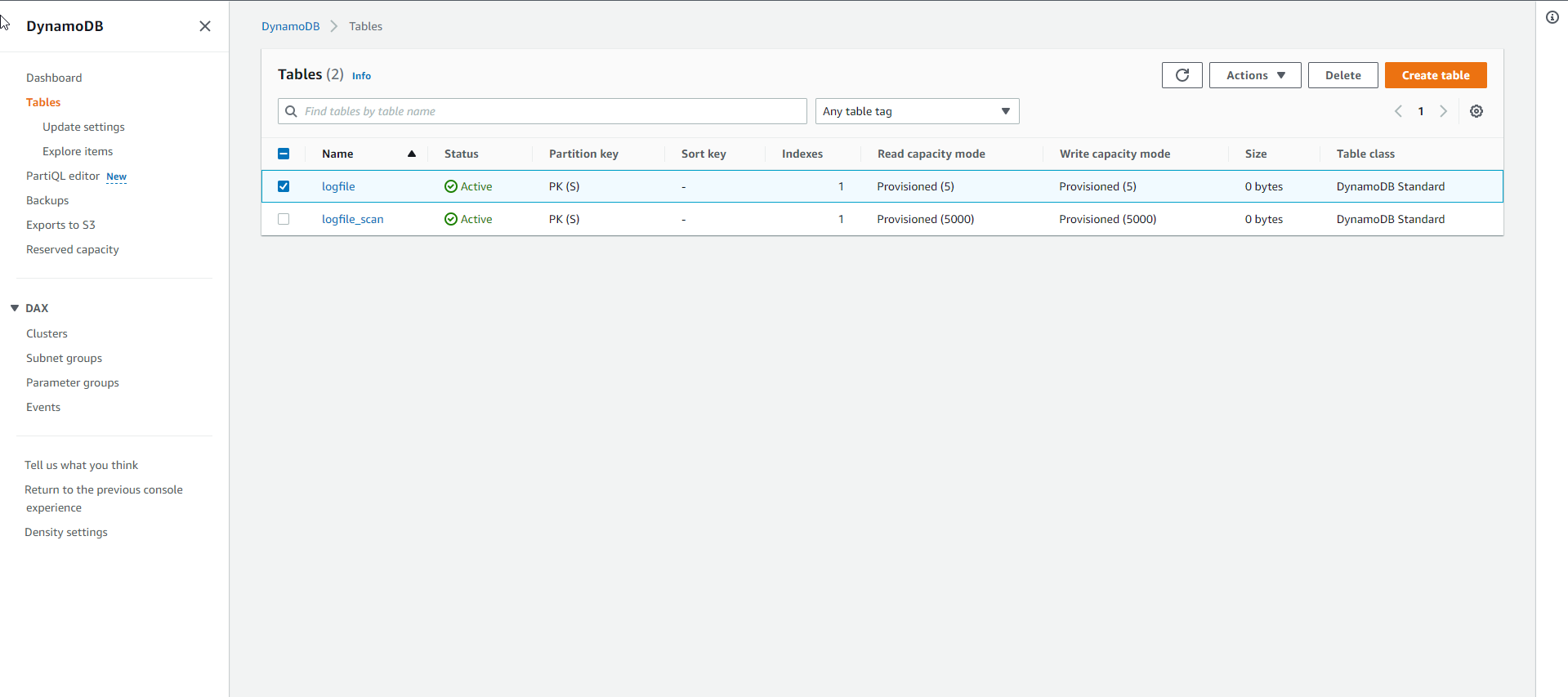
- Nạp dữ liệu mẫu vào bảng. Sau khi bảng đã được tạo, bạn có thể nạp vào dữ liệu mẫu sử dụng Python script như bên dưới:
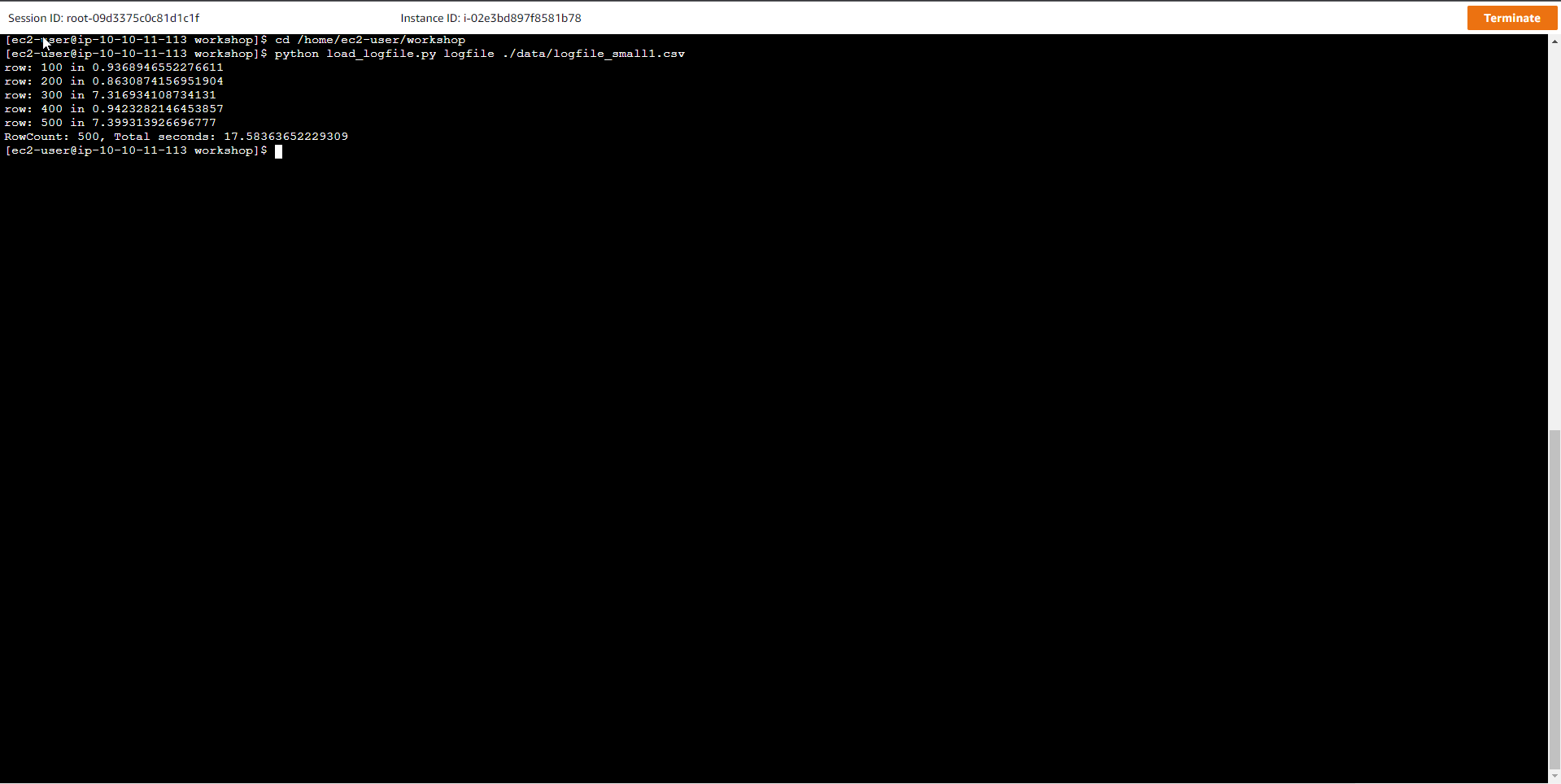
cd /home/ec2-user/workshop
python load_logfile.py logfile ./data/logfile_small1.csv
Trong đó, logfile là tên bảng, và dữ liệu mẫu nằm trong file logfile_small1.csv
row: 100 in 0.780548095703125
row: 200 in 7.2669219970703125
row: 300 in 1.547729730606079
row: 400 in 3.9651060104370117
row: 500 in 3.98996901512146
RowCount: 500, Total seconds: 17.614499807357788
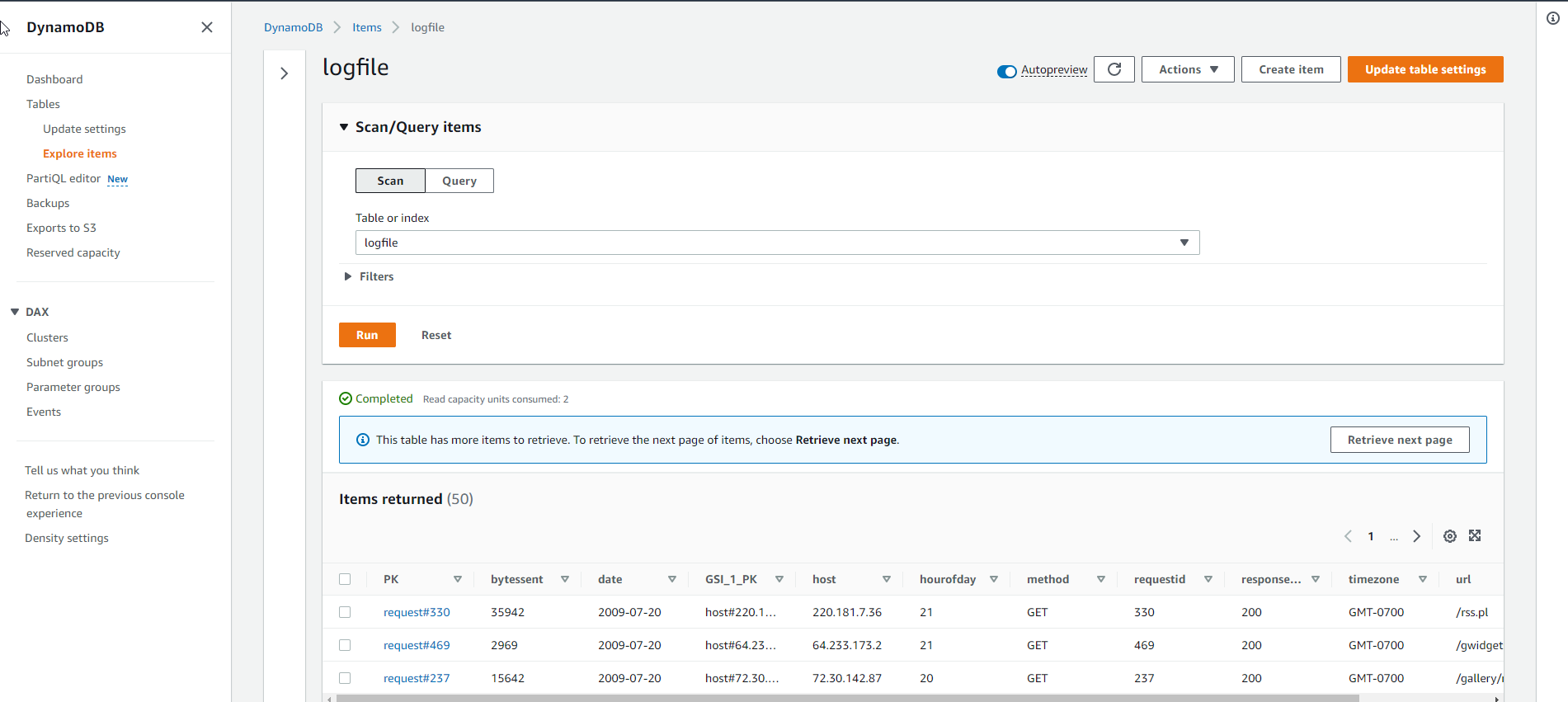
- Giao diện logfile sau khi nạp dữ liệu
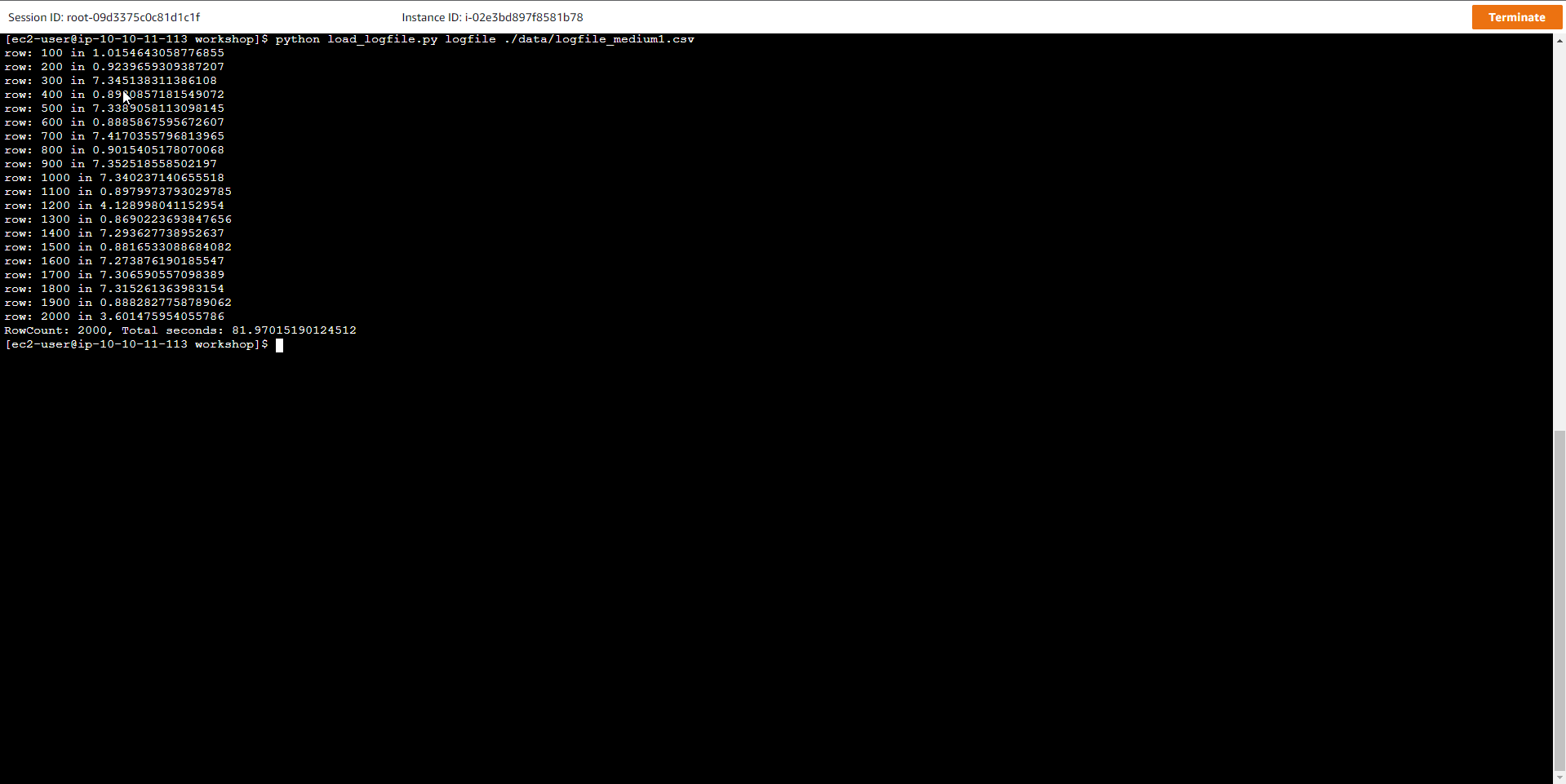
- Nạp dữ liệu mẫu kích thước lớn hơn vào bảng. Chạy lại script một lần nữa, nhưng lần này sử dụng file mẫu có kích thước lớn hơn
python load_logfile.py logfile ./data/logfile_medium1.csv
Trong đó, logfile là tên bảng, còn logfile_medium1.csv là tên của file dữ liệu mẫu.
Kết quả của script trên như bên dưới, nó cho thấy việc nạp dữ liệu ngày càng chậm hơn và mất khoảng từ 1 tới 3 phút để hoàn thành
row: 100 in 0.490761995316
...
row: 2000 in 3.188856363296509
RowCount: 2000, Total seconds: 75.0764648914
hoặc
row: 100 in 0.490761995316
...
row: 2000 in 18.479122161865234
RowCount: 2000, Total seconds: 133.84829711914062
Lưu ý rằng, thời gian nạp cho mỗi mẻ 100 dòng (bản ghi) loanh quanh khoảng 5s. Khi có quá nhiều mẻ được ghi xuống như vậy, xảy ra tình trạng tắc nghẽn, khiến Boto3 SDK làm chậm tốc độ chèn (hay lùi theo cấp số nhân). Lúc này DynamoDB sẽ cần bổ sung thêm dung lượng để đáp ứng hiệu năng nạp dữ liệu. Trong Amazon CloudWatch, thông tin liên quan tới sự nghẽn khi nạp dữ liệu thể hiển bởi metric có tên WriteThrottleEvents
- Kiểm tra CloudWatch Metrics của bảng.
- Truy cập vào DynamoDB
- Chọn Table
- Chọn bảng logfile
- Chọn Monitor
- Xem CloudWatch metrics
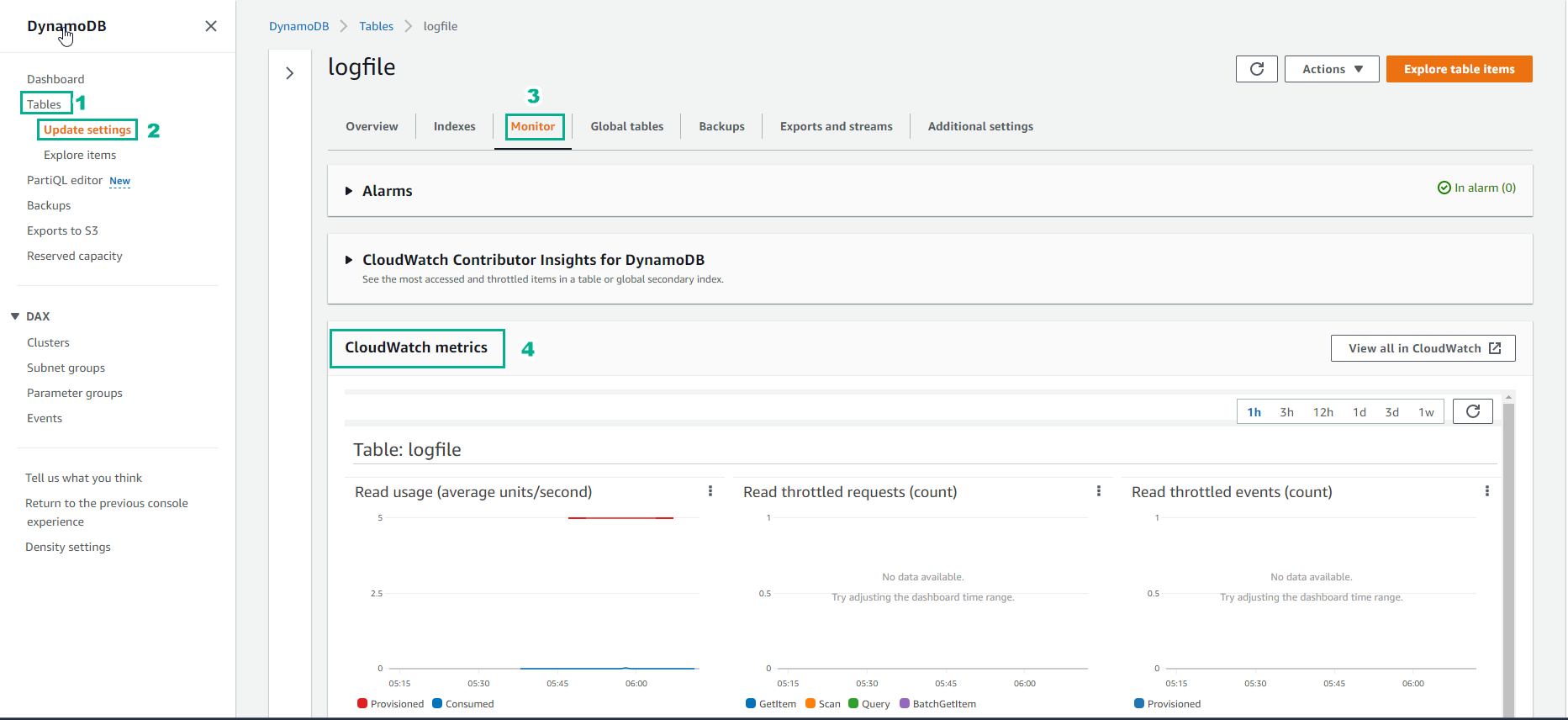
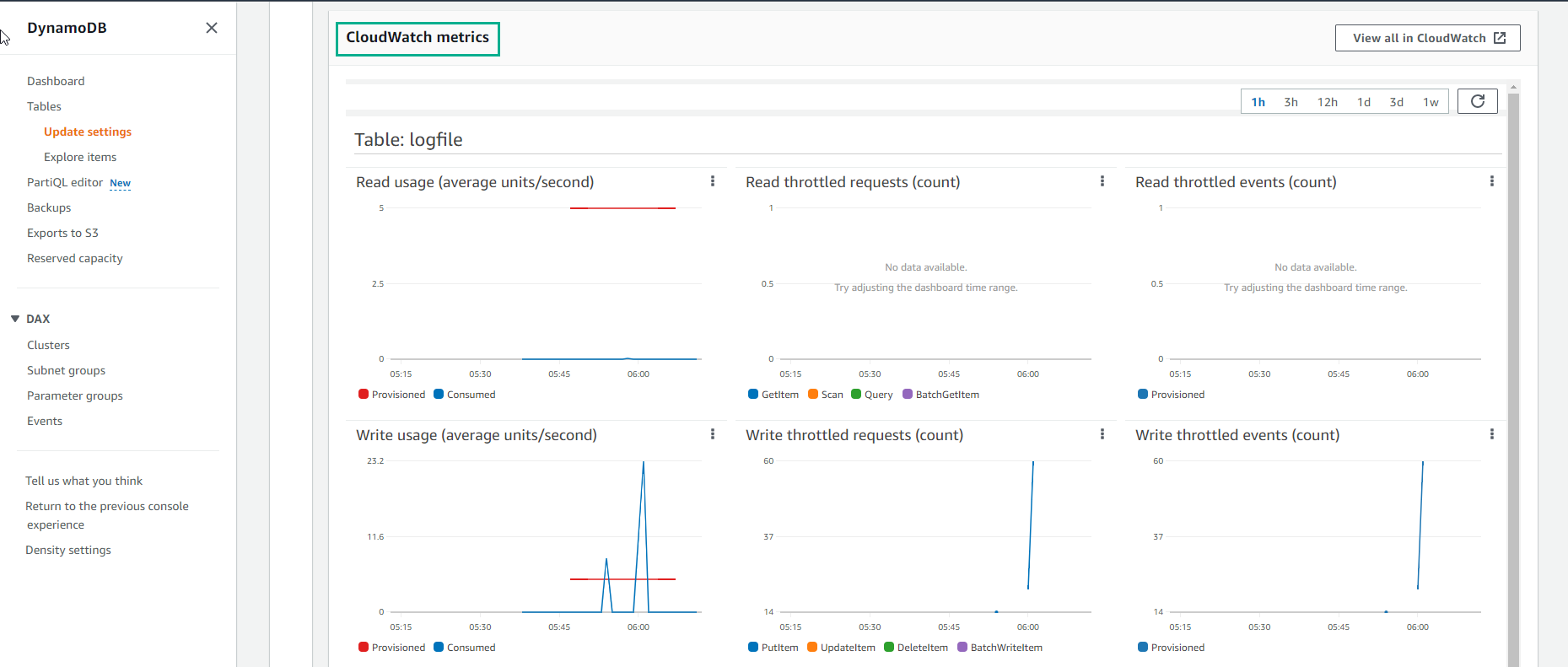
- CloudWatch metric hiển thị thông tin như bên dưới
Đối với những bảng mới tạo, sẽ mất một khoảng thời gian để thông tin về dung lượng dữ liệu đọc/ghi được thể hiện trên biểu đồ.
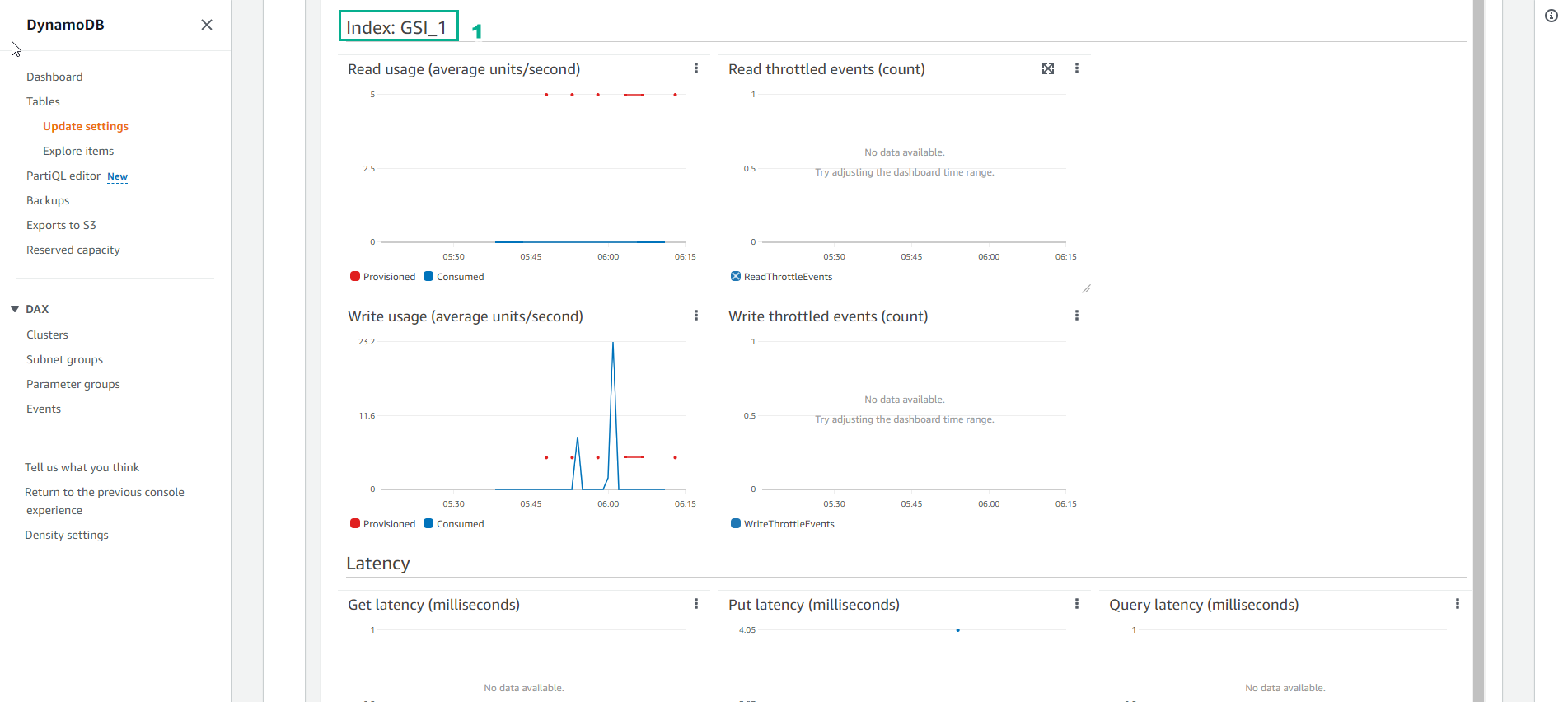
- Đối với bảng Chỉ mục GSI, CloudWatch metric sẽ hiển thị giống như bên dưới đây:
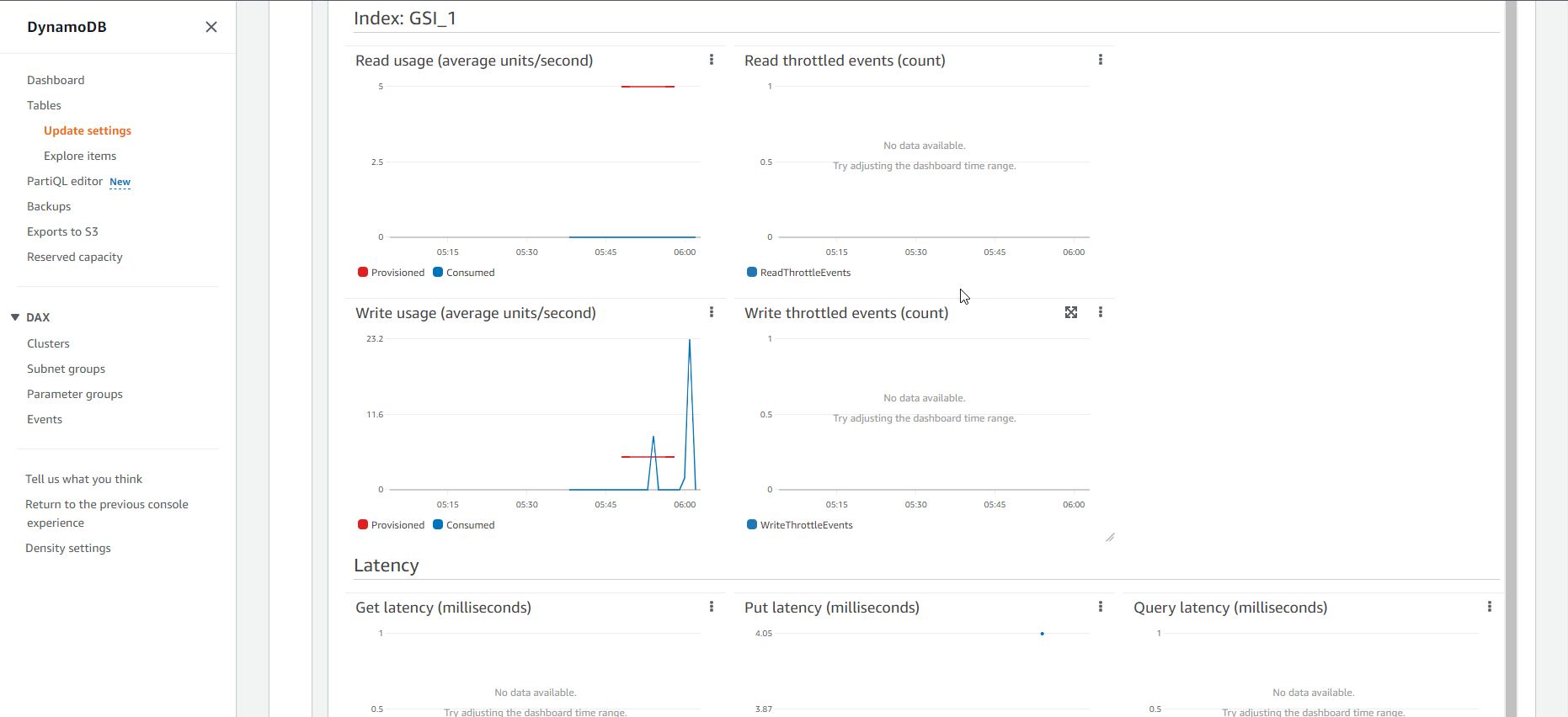
- Có thể sẽ có một số bạn thắc mắc rằng, tại sao những sự kiện về tắc nghẽn khi nạp dữ liệu không xuất hiện trong biểu đồ metric của bảng GSI, mà chỉ xuất hiện ở biểu đồ của bảng Cơ sở. Nguyên nhân đó là do giữa bảng Cơ sở và bảng Chỉ mục luôn có một buffer, chỉ khi nào capacity của bảng cơ sở bị cạn kiệt trong thời gian dài thì sự kiện tắc nghẽn mới xuất hiện trên biểu đồ của bảng Chỉ mục.
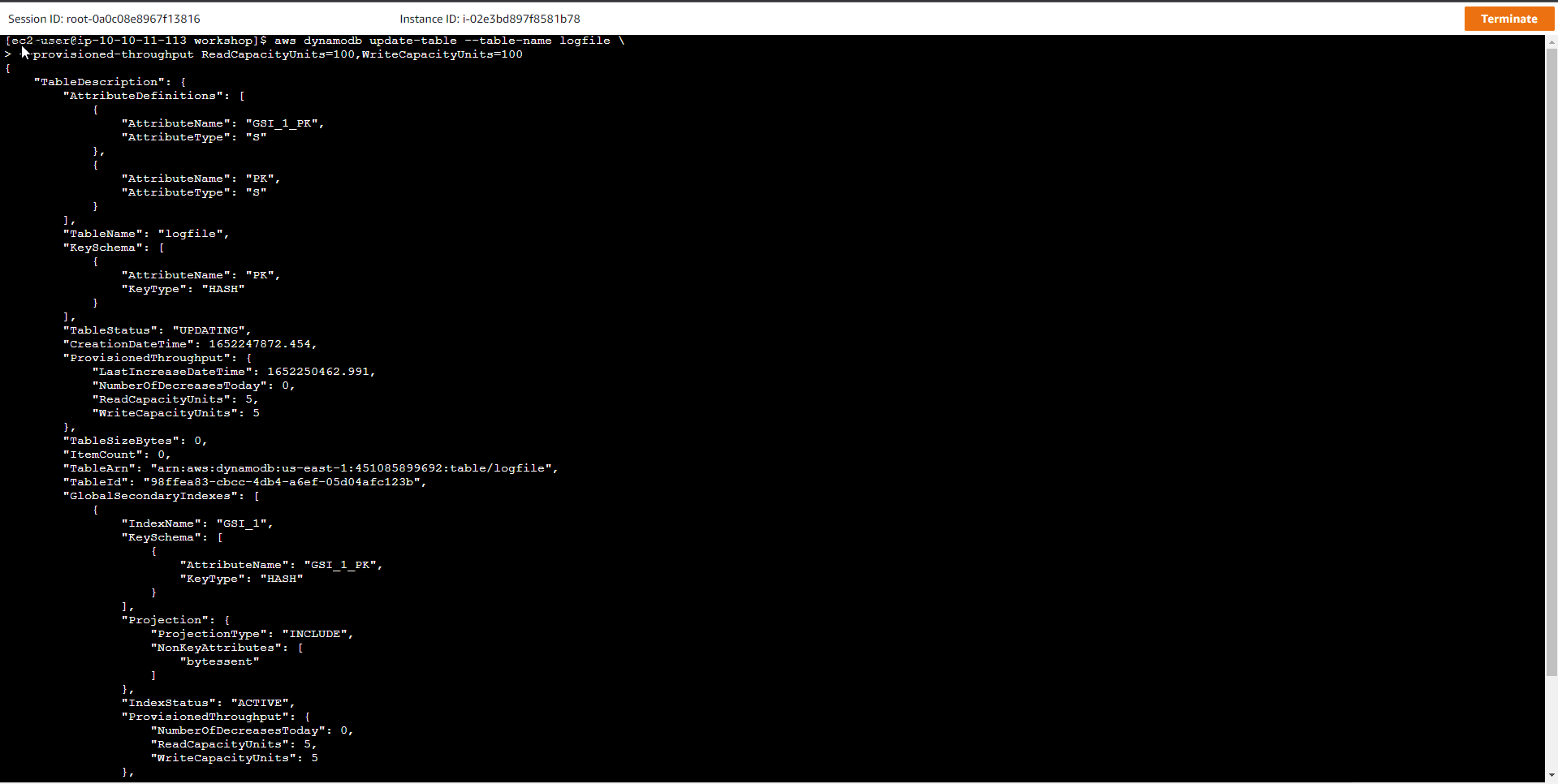
- Tăng Capacity cho bảng. Chạy lệnh tăng capacity từ 5 lên thành 100
aws dynamodb update-table --table-name logfile \
--provisioned-throughput ReadCapacityUnits=100,WriteCapacityUnits=100
- Chạy lệnh chờ cho tới khi trạng thái bảng trở thành ACTIVE
time aws dynamodb wait table-exists --table-name logfile
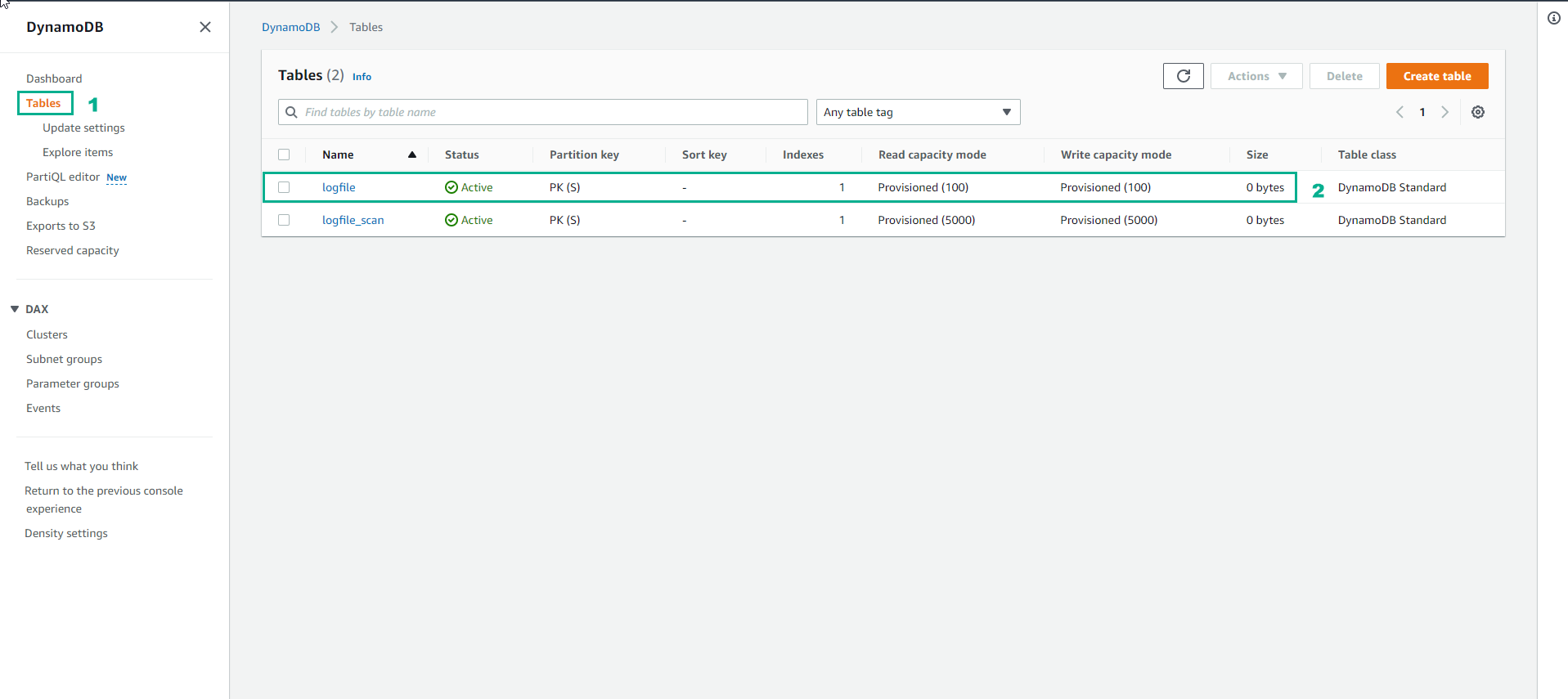
- Trong giao diện Table thấy bảng logfileđã tăng Read capacity mode và Write capacity mode lên Provisioned (100)
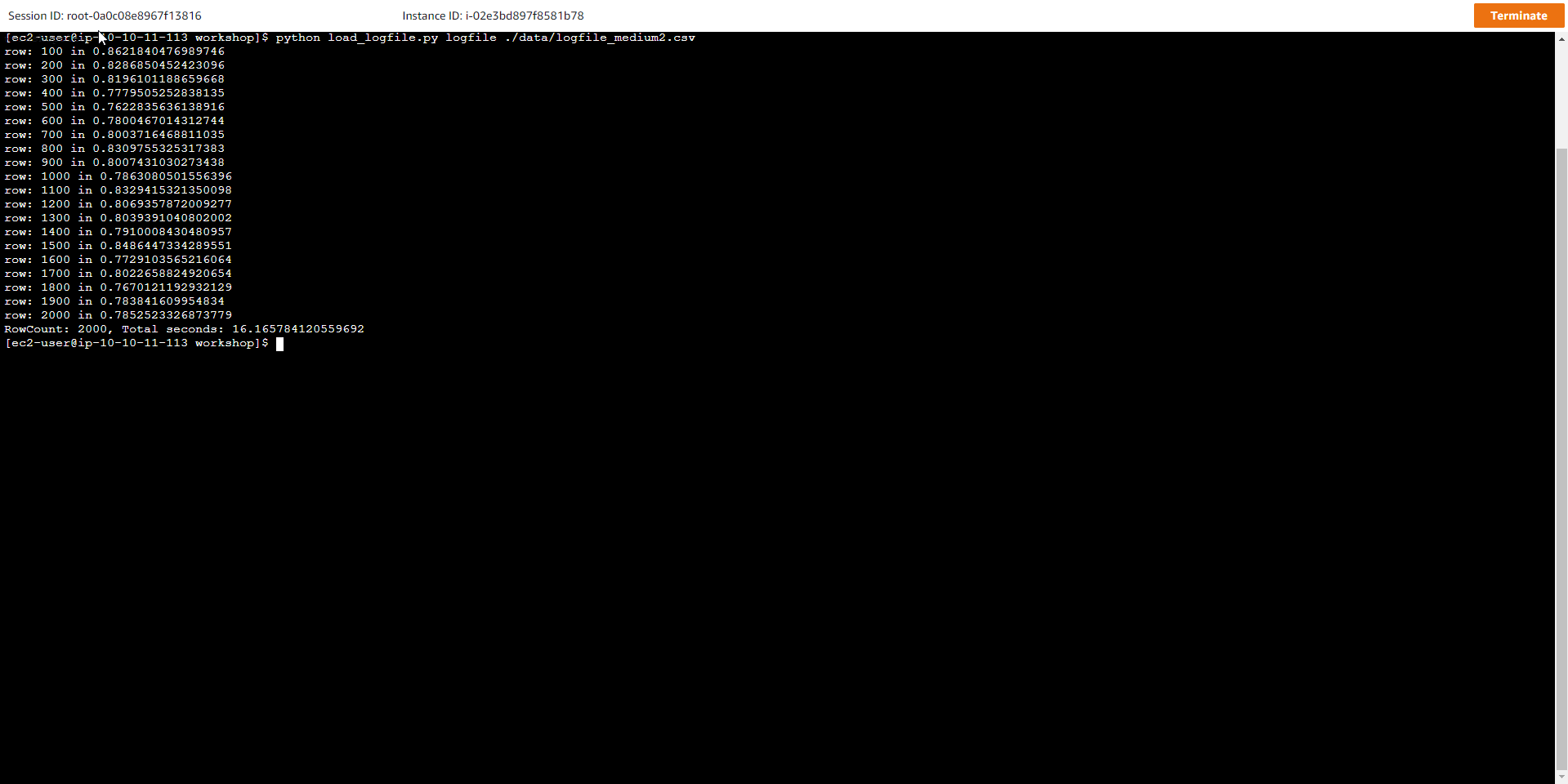
- Nạp lại dữ liệu kích thước lớn. Sau khi đã tăng thêm dung lượng xử lý cho bảng, thực hiện chạy lại script để đẩy dữ liệu từ file logfile_medium2.csv vào bảng
python load_logfile.py logfile ./data/logfile_medium2.csv
Kết quả cho thấy, tổng thời gian nạp dữ liệu nhỏ hơn so với khi thực hiện bước trước
row: 100 in 0.9451174736022949
row: 200 in 0.8512668609619141
...
row: 1900 in 0.8499886989593506
row: 2000 in 0.8817043304443359
RowCount: 2000, Total seconds: 17.13607406616211
- Tạo bảng mới với bảng Chỉ mục GSI có capacity thấp
- Giờ chúng ta sẽ thực hiện tạo một bảng với capacity khác so với các ví dụ trên. Bảng mới sẽ có một bảng Chỉ mục GSI với capacity thấp, cụ thể write capacity là 1 WCU và read capacity là 1 RCU.
- Để tạo bảng mới, ta dùng lệnh sau:
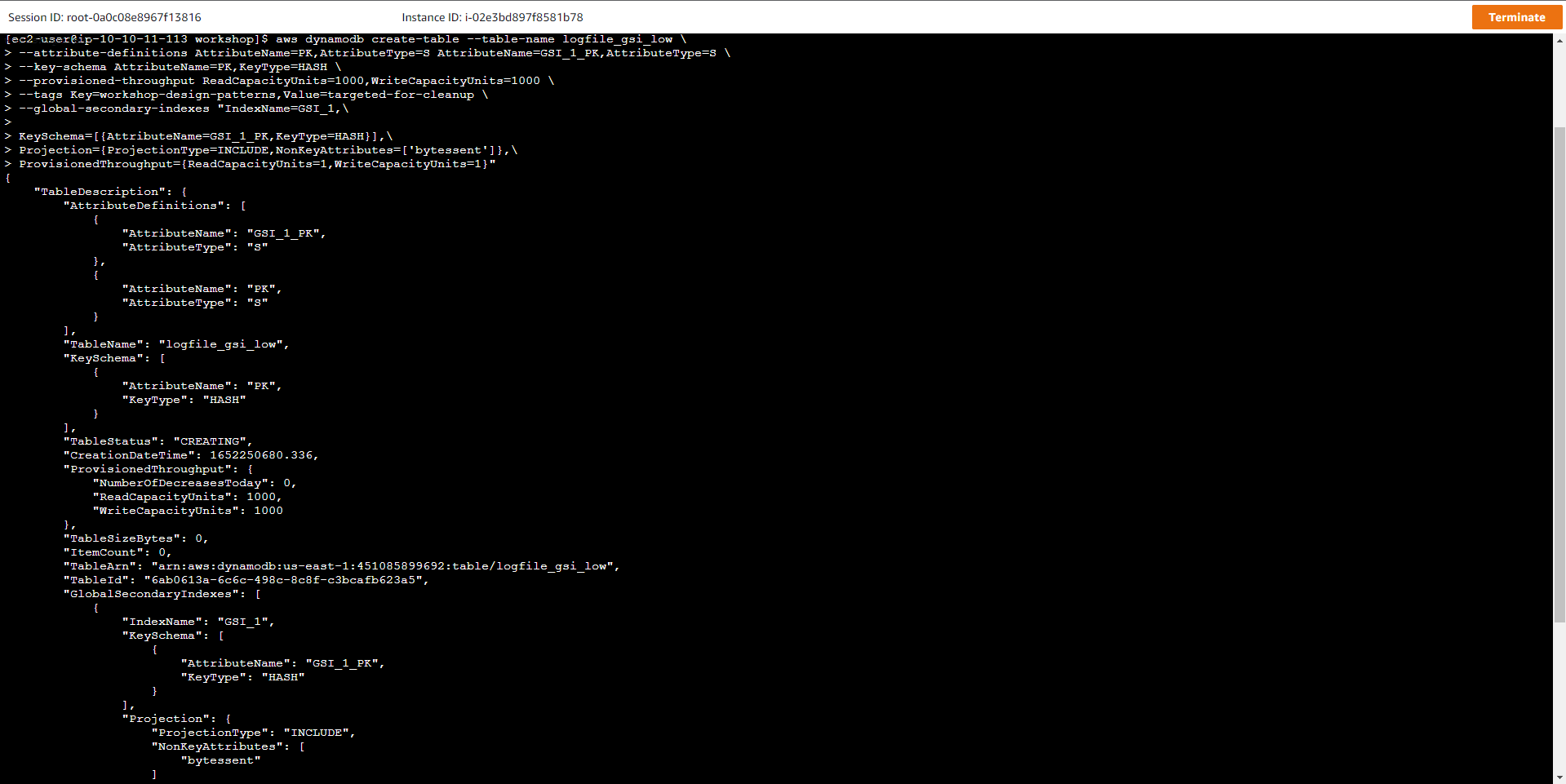
aws dynamodb create-table --table-name logfile_gsi_low \
--attribute-definitions AttributeName=PK,AttributeType=S AttributeName=GSI_1_PK,AttributeType=S \
--key-schema AttributeName=PK,KeyType=HASH \
--provisioned-throughput ReadCapacityUnits=1000,WriteCapacityUnits=1000 \
--tags Key=workshop-design-patterns,Value=targeted-for-cleanup \
--global-secondary-indexes "IndexName=GSI_1,\
KeySchema=[{AttributeName=GSI_1_PK,KeyType=HASH}],\
Projection={ProjectionType=INCLUDE,NonKeyAttributes=['bytessent']},\
ProvisionedThroughput={ReadCapacityUnits=1,WriteCapacityUnits=1}"
- Chạy lệnh đợi cho đến khi bảng chuyển trạng thái ACTIVE
aws dynamodb wait table-exists --table-name logfile_gsi_low
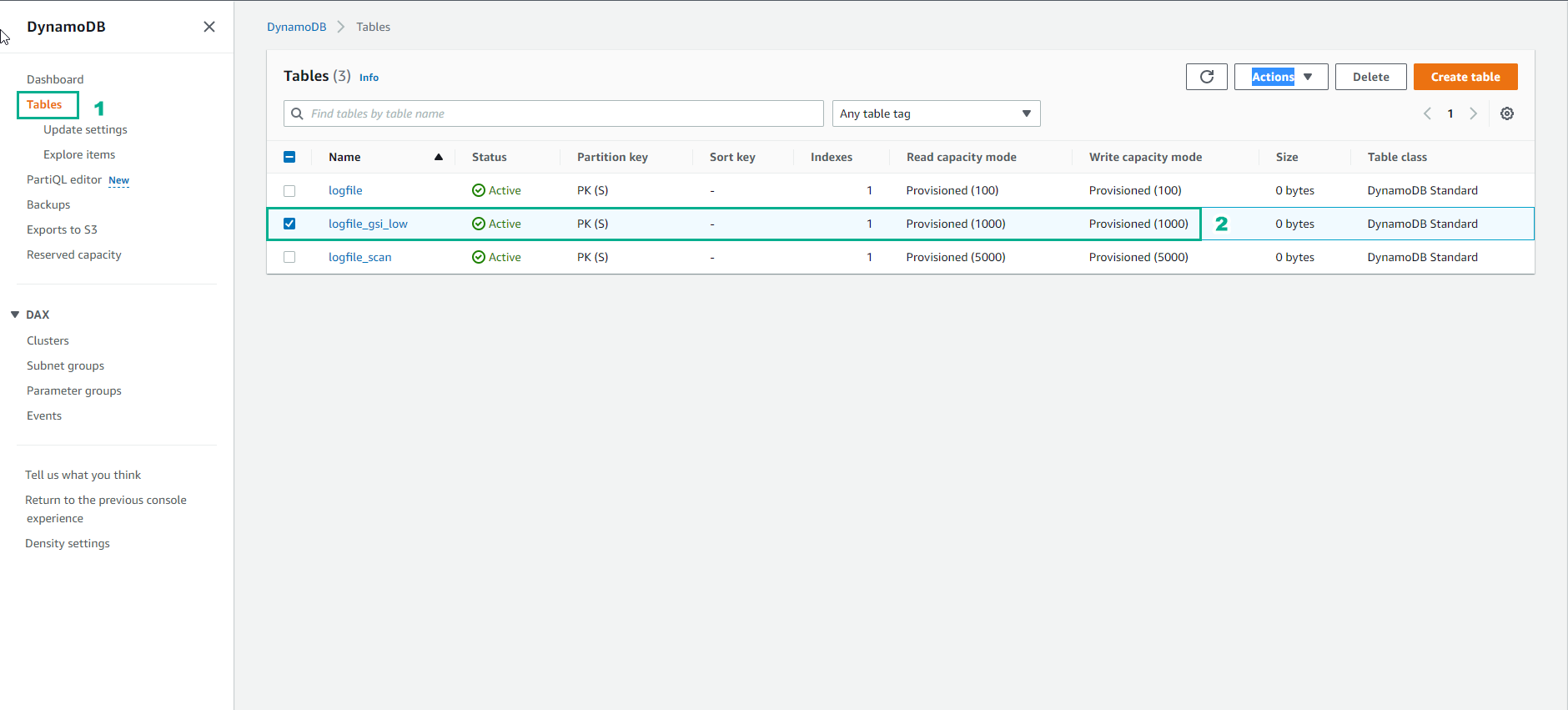
- Trong giao diện bảng của DyanmoDB, bảng logfile_gsi_low đã được tạo và trang thái Active
Lệnh tạo ra bảng logfile_gsi_low với:
-
Key schema: HASH (partition key)
-
Table read capacity units (RCUs) = 1000
-
Table write capacity units (WCUs) = 1000
-
Global secondary index: GSI_1 (1 RCU, 1 WCU) - cho phép truy vấn với địa chỉ IP của host
- Sau đó ta thực hiện đẩy một tập dữ liệu lớn vào bảng mới tạo, mục đích để giả lập sự gia tăng lưu lượng, tạo ra sự xung đột giữa dung lượng được cấp và dung lượng thực tế cần.
python load_logfile_parallel.py logfile_gsi_low
- Sau một vài phút thực thi, một thông báo lỗi xuất hiện cho biết đã xảy ra sự tắc nghẽn dữ liệu và cần tăng thêm dung lượng được cấp cho bảng DynamoDB, hoặc bật tính năng autoscale cho bảng.
ProvisionedThroughputExceededException: An error occurred (ProvisionedThroughputExceededException) when calling the BatchWriteItem operation (reached max retries: 9): The level of configured provisioned throughput for one or more global secondary indexes of the table was exceeded. Consider increasing your provisioning level for the under-provisioned global secondary indexes with the UpdateTable API
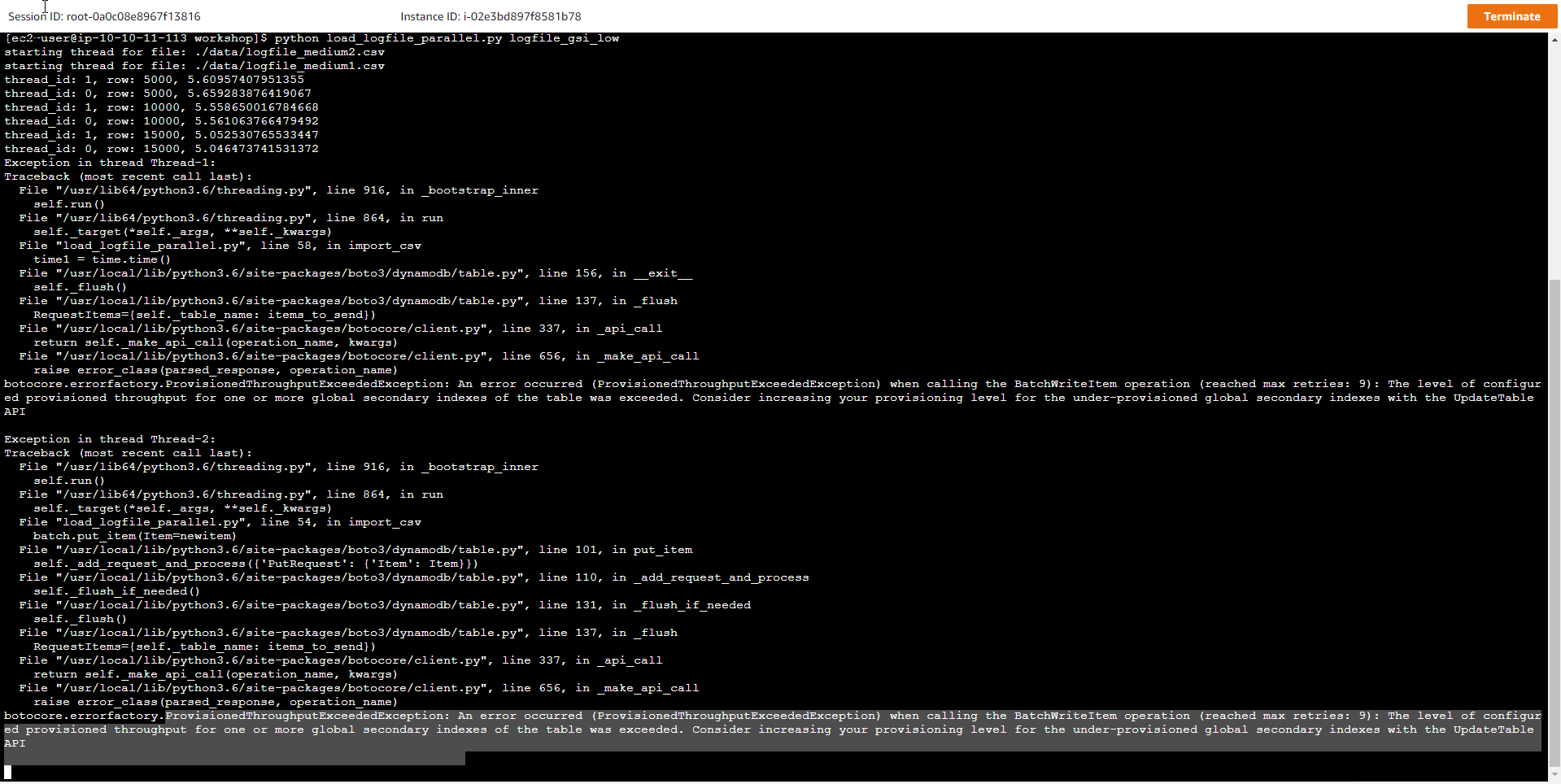
Câu hỏi đặt ra ở đây là, tại sao bảng mới của chúng ta có WCU=1000 và RCU=1000 nhưng vẫn xảy ra tình trạng tắc nghẽn khi ghi dữ liệu từ file mới vào bảng, đồng thời thời gian nạp dữ liệu cũng tăng lên rất nhiều. Xem xét kĩ lại thông báo lỗi có thể thấy rằng, ngoại lệ có tên ProvisionedThroughputExceededException đã bắt được lỗi tắc nghẽn dữ liệu, cụ thể thông lượng được cấp cho bảng Chỉ mục GSI đã bị vượt quá. Như vậy chúng ta sẽ phải tăng thêm dung lượng xử lý cho bảng Chỉ mục, vì hiện tại dung lượng cấp cho bảng Chỉ mục vô cùng thấp với 1 RCU và 1 WCU. Theo nguyên lý hoạt động, nếu bạn muốn bảng Cơ sở hoạt động với 100% write capacity được cấp, thì bảng Chỉ mục tương ứng cũng phải có dung lượng Ghi bằng với dung lượng Ghi của bảng Cơ sở. Trong trường hợp này, Dung lượng Ghi của bảng Chỉ mục cần phải được thiết lập lại WCU=1000
- Nguyên nhân xảy ra lỗi và cách khắc phục đã rất rõ ràng. Nhưng nếu ta muốn xem xét thêm với CloudWatch metric, thì tại trang DynamoDB console, nhấp vào Table rồi chọn bảng có tên logfile_gsi_low.
- Chọn Write usage
- Chọn View in metrics
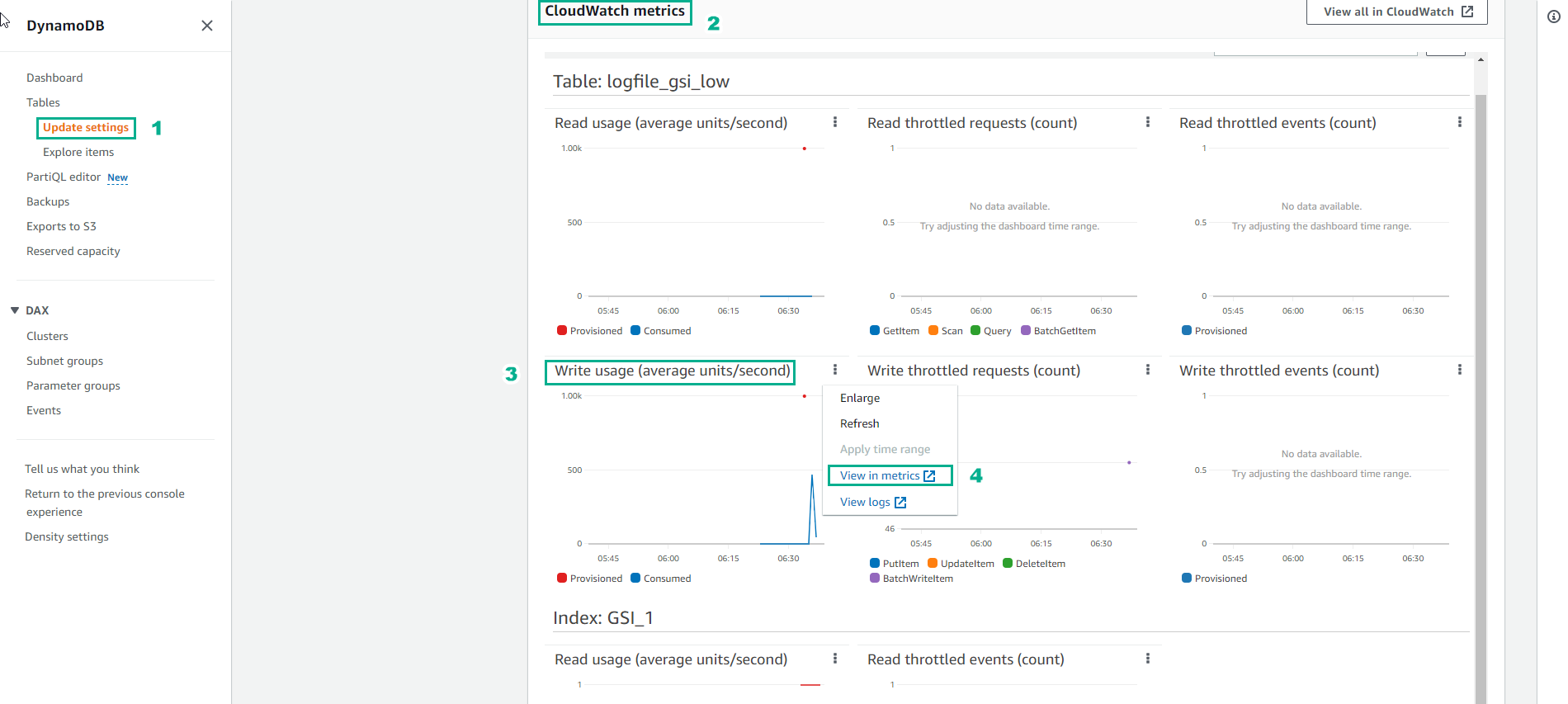
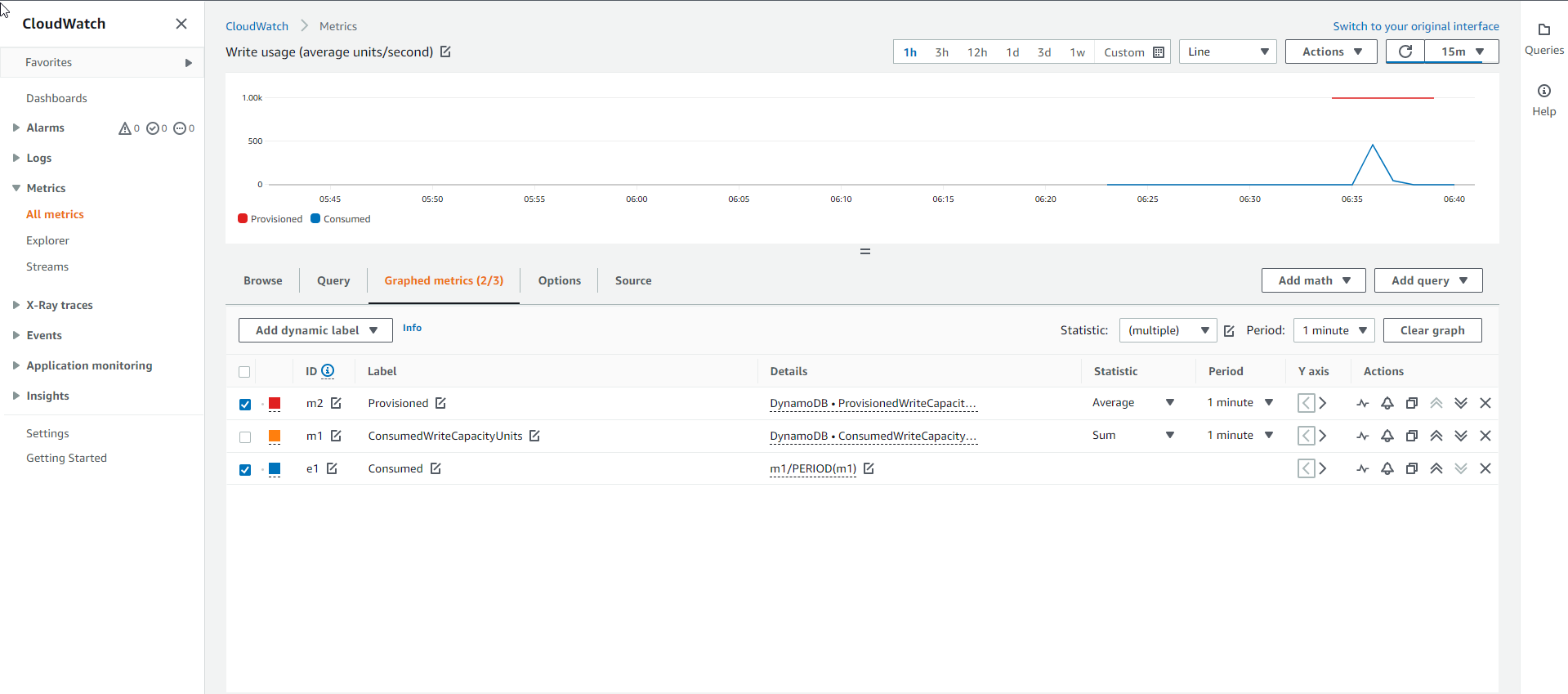
- Hình ảnh bên dưới thể hiện biểu đồ dung lượng Ghi của bảng Cơ sở. Đường màu xanh cho biết dung lượng ghi tiêu thụ thực tế, còn đường màu đỏ là dung lượng ghi được cấp. Do đường màu xanh nằm bên dưới đường màu đó, nên có thể kết luận rằng bảng Cơ sở có dung lượng Ghi phù hợp với sự gia tăng yêu cầu đột ngột.
- Xem phần Index: GSI_1
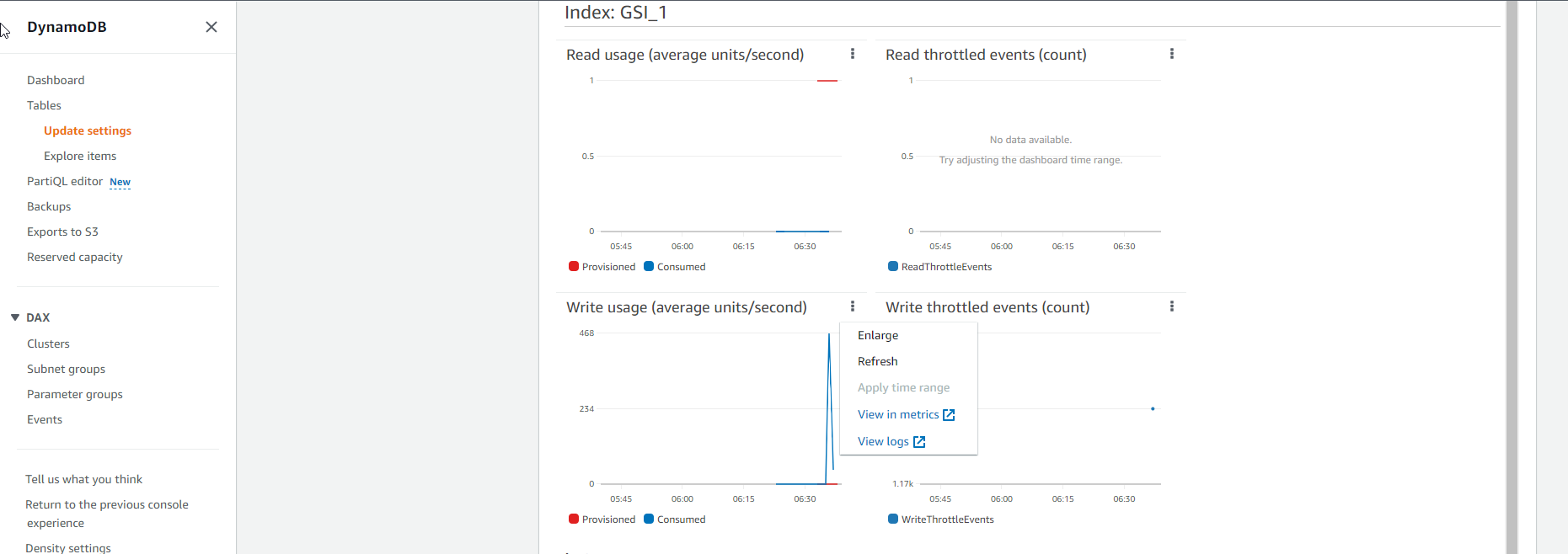
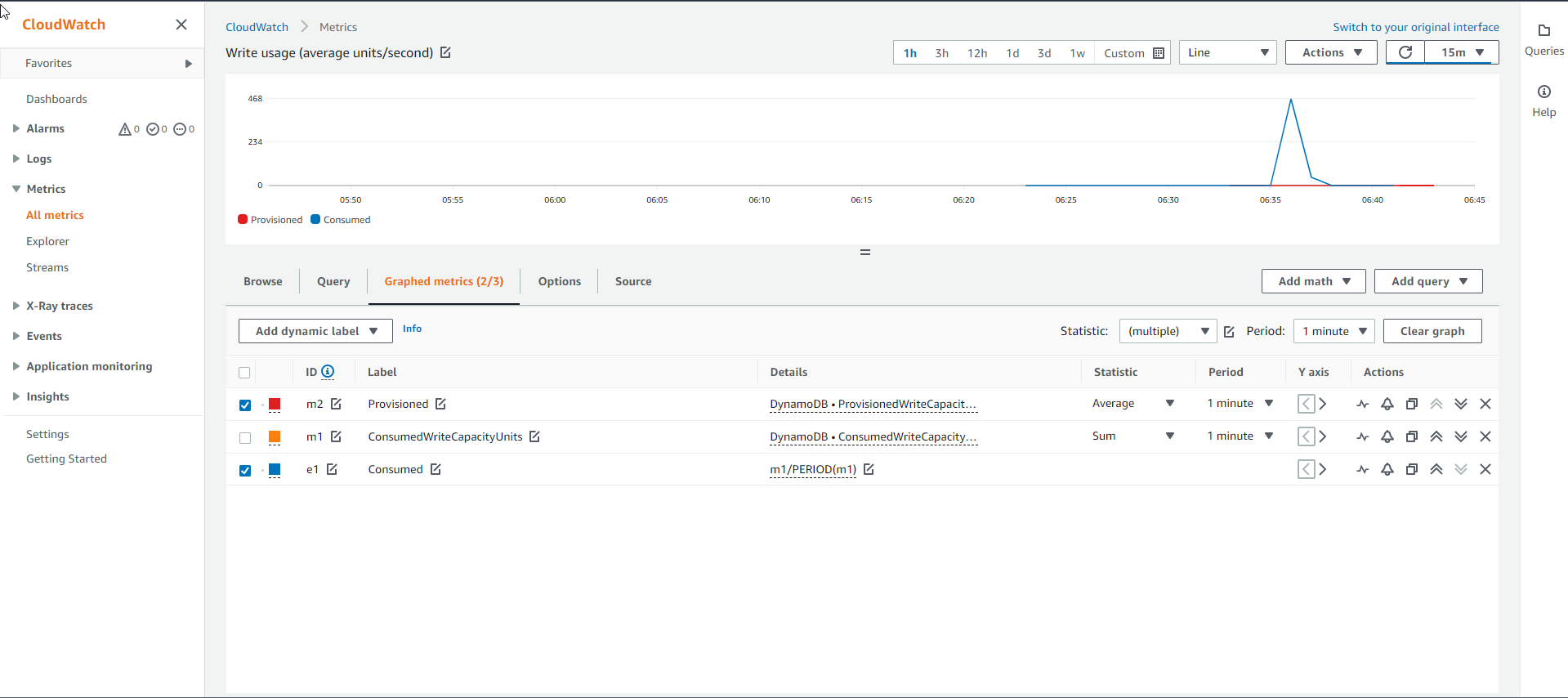
- Còn với biểu đồ dung lượng Ghi của bảng Chỉ mục như bên dưới thì lại cho thấy đường dung lượng Ghi tiêu thụ thực tế (đường màu xanh) đang nằm ở trên đường dung lượng Ghi được cấp (đường màu đỏ). Điều này chứng tỏ bảng Chỉ mục GSI cần được cấp thêm capacity để đáp ứng sự gia tăng yêu cầu đột ngột.
- Mặc dù bảng Cơ sở logfile_gsi_low có dung lượng Ghi đã đáp ứng, tuy nhiên khi kiểm tra biểu đồ Throttled write requests thì vẫn thấy xuất hiện đường thể hiện số lượng request bị tắc nghẽn. Mọi API request mà bị tắc nghẽn đều được ghi vào biểu đồ ThrottledRequests metrics. Như hình bên dưới ta thấy, có tới hơn 20 API request bị tắc nghẽn.
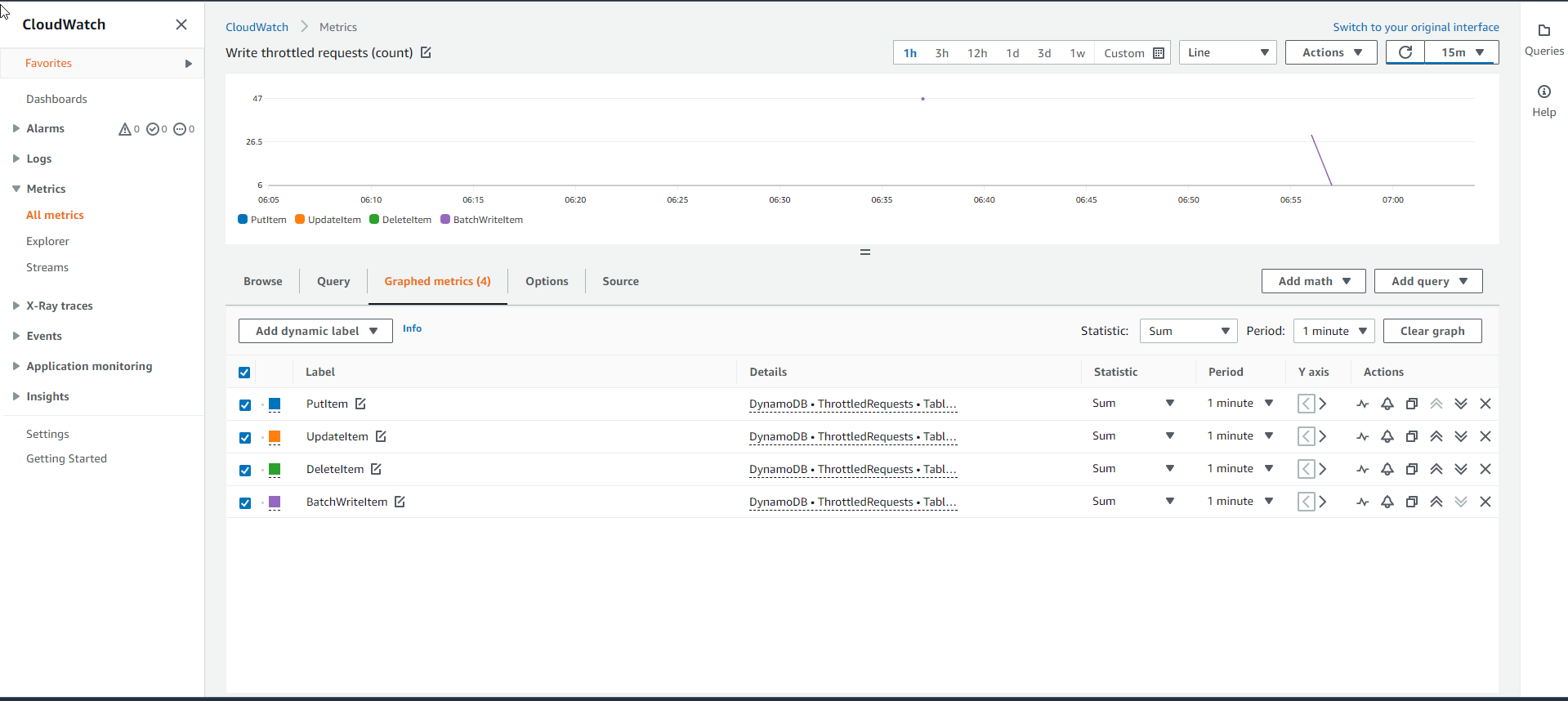
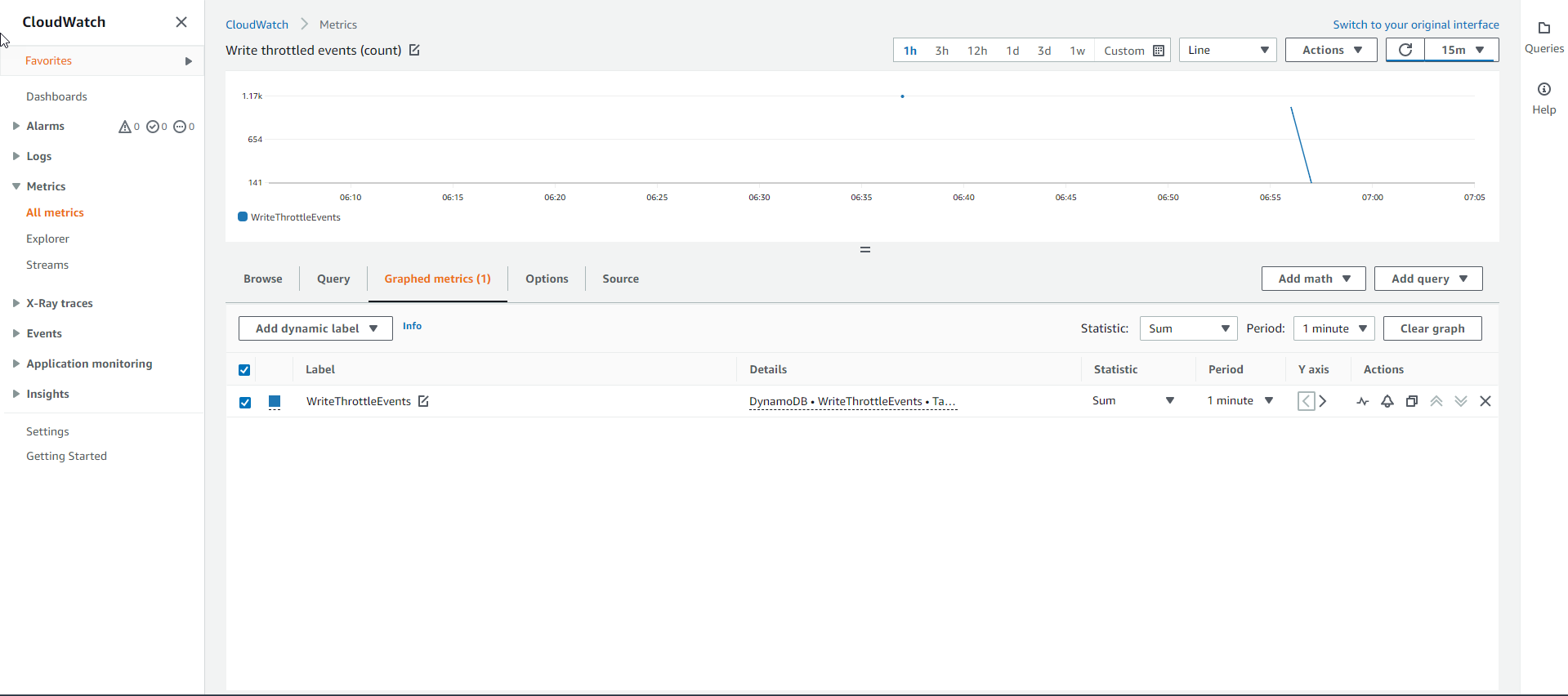
- Để xác định nguồn gốc gây ra sự tắc nghẽn của các Write request, ta sẽ cần kiểm tra biểu đồ Throttled Write Events metric. Nếu bảng Cơ sở là nguồn gốc gây ra sự tắc nghẽn thì nó sẽ phải có WriteThrottleEvents, ngược lại là bảng Chỉ mục GSI.
- Và sau khi kiểm tra, ta thấy chỉ có bảng Chỉ mục GSI là có WriteThrottleEvents với biểu đổ như bên dưới. Nguyên nhân có thể hiểu được là do bảng Chỉ mục không có đủ Write capacity để đáp ứng sự gia tăng yêu cầu đột ngột. Như vậy bảng Chỉ mục chính là nguyên nhân gây ra sự tắc nghẽn cho các Write request.
Kết luận:
- Capacity của bảng DynamoDB là riêng biệt so với capacity của bảng Chỉ mục GSI. Nếu bảng Chỉ mục không được cấp đủ capacity, nó có thể tạo ra áp lực ngược lên các bảng Cơ sở dưới dạng tắc nghẽn khi nạp dữ liệu.
- Nó sẽ khiến tất cả các yêu cầu ghi vào bảng Cơ sở bị từ chối cho đến khi bộ đệm giữa bảng Cơ sở và bảng Chỉ mục GSI được giải phóng và có đủ không gian cho dữ liệu mới.
- Hãy luôn theo dõi các chỉ số CloudWatch trên cả bảng Cơ sở và bảng Chỉ mục, đồng thời đặt cảnh báo giám sát dựa trên yêu cầu kinh doanh của bạn.