Sequential and parallel table scans
Sequential and parallel table data scanning
Overview
Although DynamoDB distributes items across different physical partitions, the Scan operation can only read one partition at a time. Thus the throughput of the Scan operation is limited by the maximum throughput of a partition.
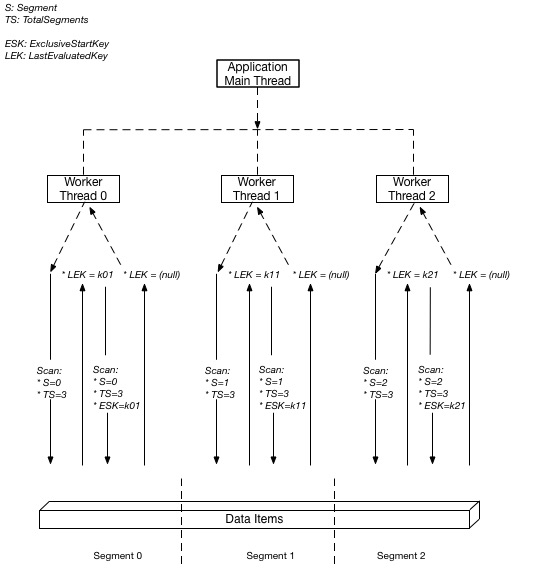
To maximize the Table-level Scan operation, we use Parallel Scan to split a Logical Base table (or GSI Index table) into multiple logical segments and use multiple application handlers to scan parallelize these logical segments.
Each worker application handler can be a thread in programming languages that support multithreading, or it can be an operating system process.
The diagram below depicts how a multithreaded application performs a Parallel Scan with three application processing threads. The application creates three threads and each thread issues a Scan request and then scans the segments to which it has been assigned. The data obtained after the scan command is returned to the main application thread with a size not exceeding 1 MB.
Practice
- The first step we execute a Sequential Scan command to calculate the total number of bytes sent for records with response code <> 200. The Scan command can be combined with a filter expression to filter out irrelevant records. The application handler then sums the sent bytes of all records with response code <> 200.
- Here we have prepared the scan_logfile_simple.py file, which includes the command to run Scan with a filter expression and then perform the summation of the sent bytes.
The content of the instruction code that performs the table data scan
fe = "responsecode <> :f"
eav = {":f": 200}
response = table.scan(
FilterExpression=fe,
ExpressionAttributeValues=eav,
Limit=pageSize,
ProjectionExpression='bytessent')
The number of items that the Scan operation can read depends on the maximum number of items set (if using the Limit parameter) or up to 1 MB of data, then apply any filter to the results using Use FilterExpression. If the total number of items scanned exceeds the maximum set by the Limit parameter or exceeds the dataset size limit of 1 MB, the scan will stop and the result is returned to the user as a LastEvaluatedKey value. .
In the code below, the LastEvaluatedKey value is passed to the Scan method via the ExclusiveStartKey parameter.
while 'LastEvaluatedKey' in response:
response = table.scan(
FilterExpression=fe,
ExpressionAttributeValues=eav,
Limit=pageSize,
ExclusiveStartKey=response['LastEvaluatedKey'],
ProjectionExpression='bytessent')
for i in response['Items']:
totalbytessent += i['bytessent']
Until the last records are returned, the LastEvaluatedKey parameter value is no longer part of the feedback, meaning the scan is over.
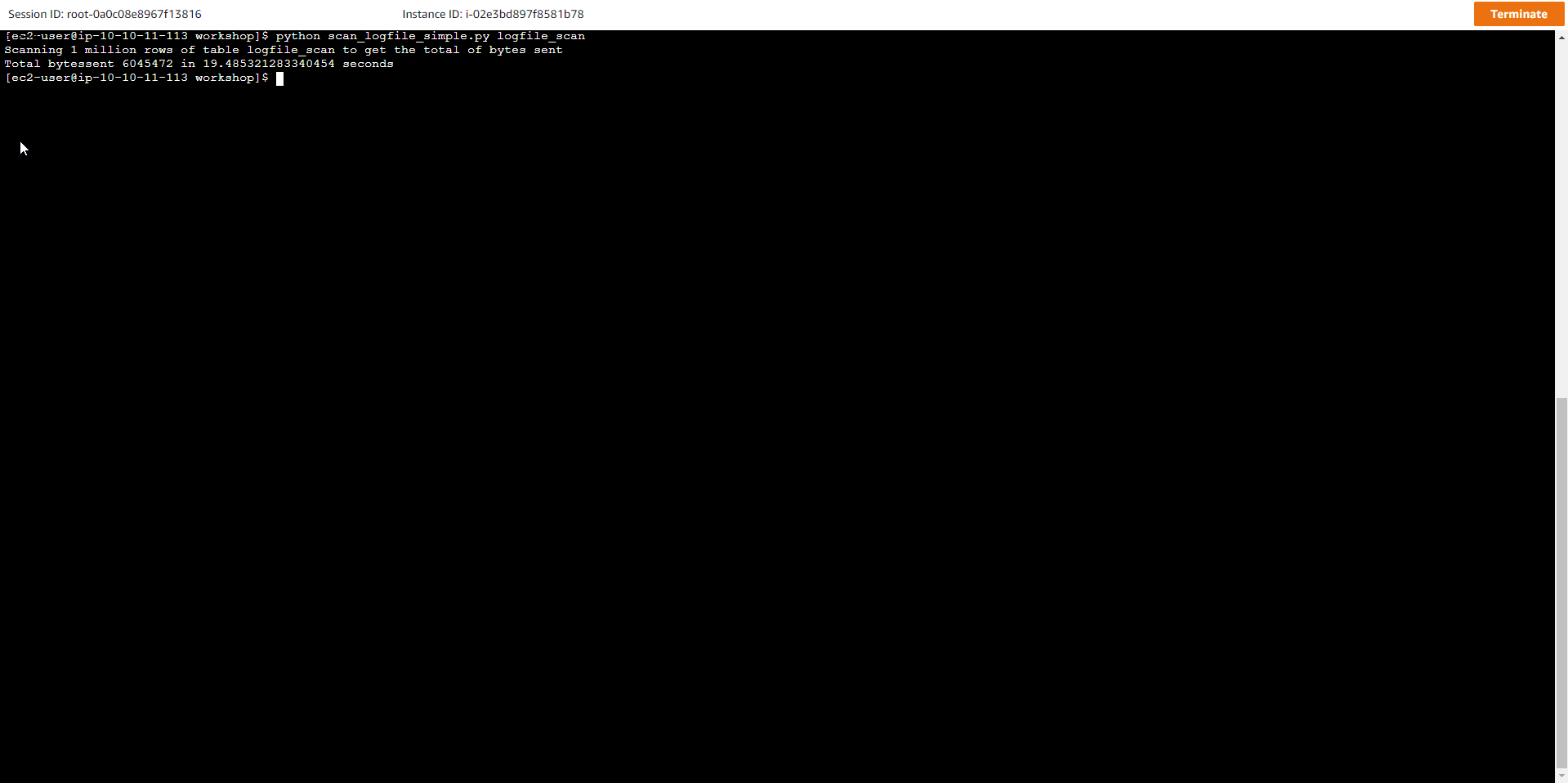
Now let’s execute the code below
python scan_logfile_simple.py logfile_scan
Where the table name is logfile_scan The output is similar to the following:
Scanning 1 million rows of table logfile_scan to get the total of bytes sent
Total bytessent 6054250 in 16.325594425201416 seconds
Save completion times with Sequential Scan. Then we move on to the next step.
- Practice Parallel Scan
-
To perform a Parallel Scan, each application handler must issue its Scan request with the following parameters:
-
Segment: Each segment is scanned by a specific application handler so each Segment should have a different representation value
-
TotalSegments: the Total number of segments in the parallel scan. This value should be equal to the number of handlers the application will use.
The content of the code that performs parallel scanning is in the file scan_logfile_parallel.py
fe = "responsecode <> :f"
eav = {":f": 200}
response = table.scan(
FilterExpression=fe,
ExpressionAttributeValues=eav,
Limit=pageSize,
TotalSegments=totalsegments,
Segment=threadsegment,
ProjectionExpression='bytessent'
)
After the first scan, the scan continues until the LastEvaluatedKey parameter value equals null.
while 'LastEvaluatedKey' in response:
response = table.scan(
FilterExpression=fe,
ExpressionAttributeValues=eav,
Limit=pageSize,
TotalSegments=totalsegments,
Segment=threadsegment,
ExclusiveStartKey=response['LastEvaluatedKey'],
ProjectionExpression='bytessent')
for i in response['Items']:
totalbytessent += i['bytessent']
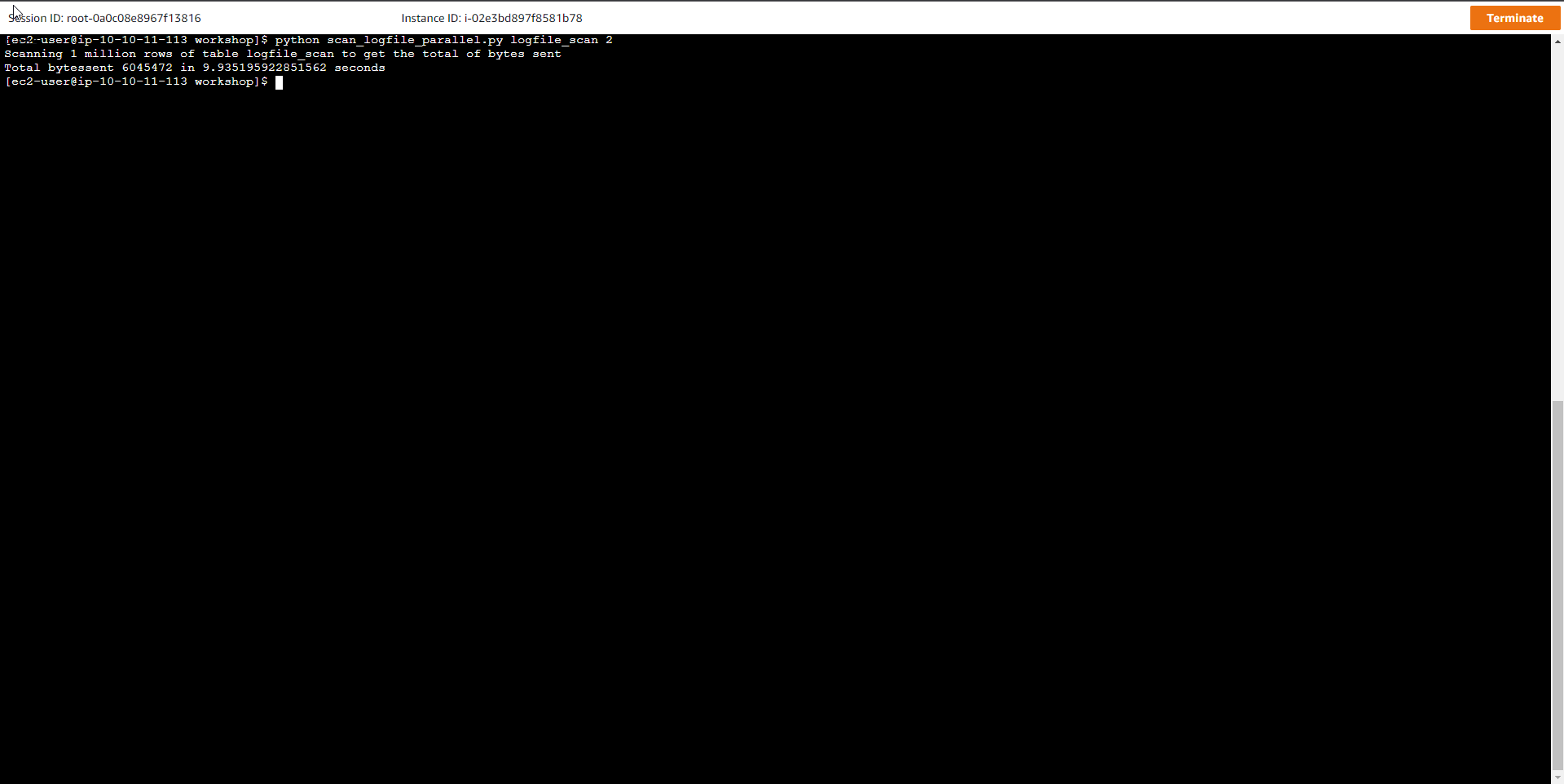
Execute the script to start the Parallel Scan execution
python scan_logfile_parallel.py logfile_scan 2
Where the table name is logfile_scan, the number of threads or handlers is 2.
The result after the scan command is that the parallel scan time is much shorter than the sequential scan. The difference can be even bigger if the data table contains a larger number of items.
Scanning 1 million rows of the `logfile_scan` table to get the total of bytes sent
Total bytessent 6054250 in 8.544446229934692 seconds
Conclusion
-
In this exercise, we have learned and used two DynamoDB table scan methods: Sequential and Parallel, to read items from a table or GSI index table.
-
The Scan operation is an operation that consumes a large number of space resources, so it should be avoided.
-
It only makes sense when you perform a scan of a small table or the Scan operation is unavoidable (such as batch extraction of data).
However, as a general rule you should design your applications to avoid doing scans.